l3hctf - misc - WriteUp
碎碎念
首先先说一句:SU牛逼! 这次狠狠夺冠了,队里的大哥们太厉害了,这把也是给俺蹭到了)总的来说这次l3h的题目难度其实不算特别高,反而还有些特别简单 (以及特别恶心的)(没有针对出题人的意思) 但结果来说还是能做的,不过还是要继续学习啊qwq
欢迎各方向师傅大佬加入SU
有意愿加入SU的小伙伴请联系:suers_xctf@126.com 或者直接联系baozongwi师傅QQ:2405758945
量子双生影
知识点省流
ntfs数据流隐写+ai二维码变换+双图合并
WP
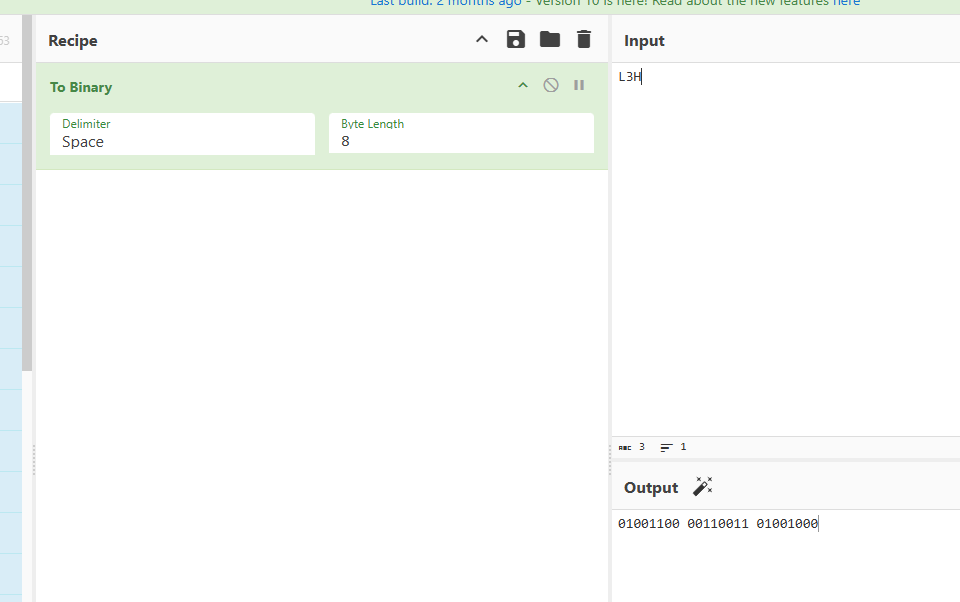
附件给了一个压缩包,打开后里面是一个webp图片,打开后不难看出是一个通过ai处理后的二维码

这时候掏出我们的lovelyqrscanner扫描一下,发现提示我们这不是flag,那就需要再找找藏了什么,这里给了一个提示quantum但不知道是什么意思
用7z打开压缩包,发现压缩包里其实还藏了一张图片,实际上这是ntfs数据流隐写(可参考这个文章https://joner11234.github.io/article/85357d8d.html)
用7z打开可以直接看到藏起来的文件,也可以用winrar解压后,用NtfsStreamsEditor去扫描目录
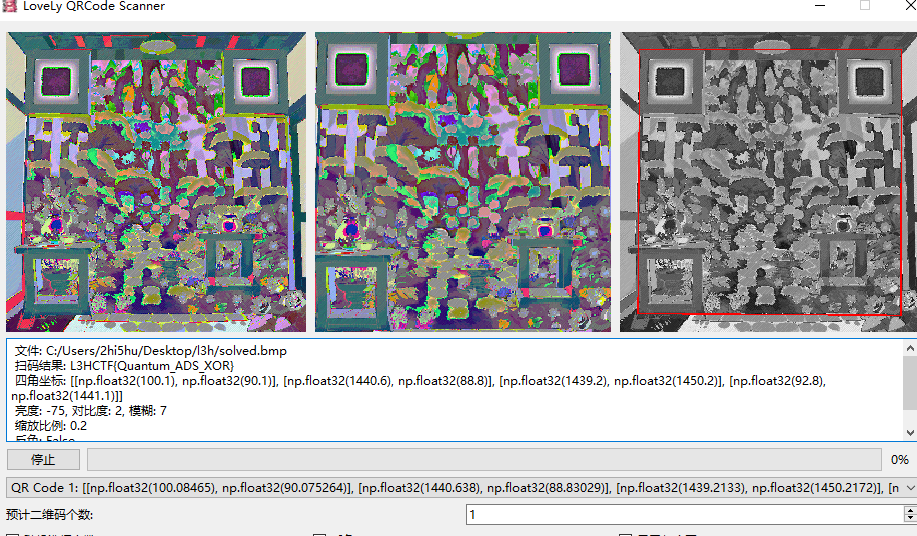
提取出来后,可以发现第二张图片乱乱的,隐约中既有第一张的内容,又混杂了其他东西,所以用stegsolve去合并处理一下,最后可以得到另一张二维码

接着扫描即可得到flag
LearnRag
知识点省流
论文题
WP
https://github.com/vec2text/vec2text
https://arxiv.org/html/2401.12192v4
还在学习中)
Why not read it out?
知识点省流
魔改密文破译
WP
非常有意思的一道题,非常有意思
附件给了一个README文件,010看看发现是jpg图片,并且在末尾看到藏了一串倒转的base64,厨子处理一下得到提示:IGN Review
修改文件后缀打开内容如下

可以看出图片中有一大段内容,而且是通过某种文字表达出来,所以我们对文字简单社工一下,确定这些文字来自于tunic这个游戏,这是一种由游戏作者自创的音标文字
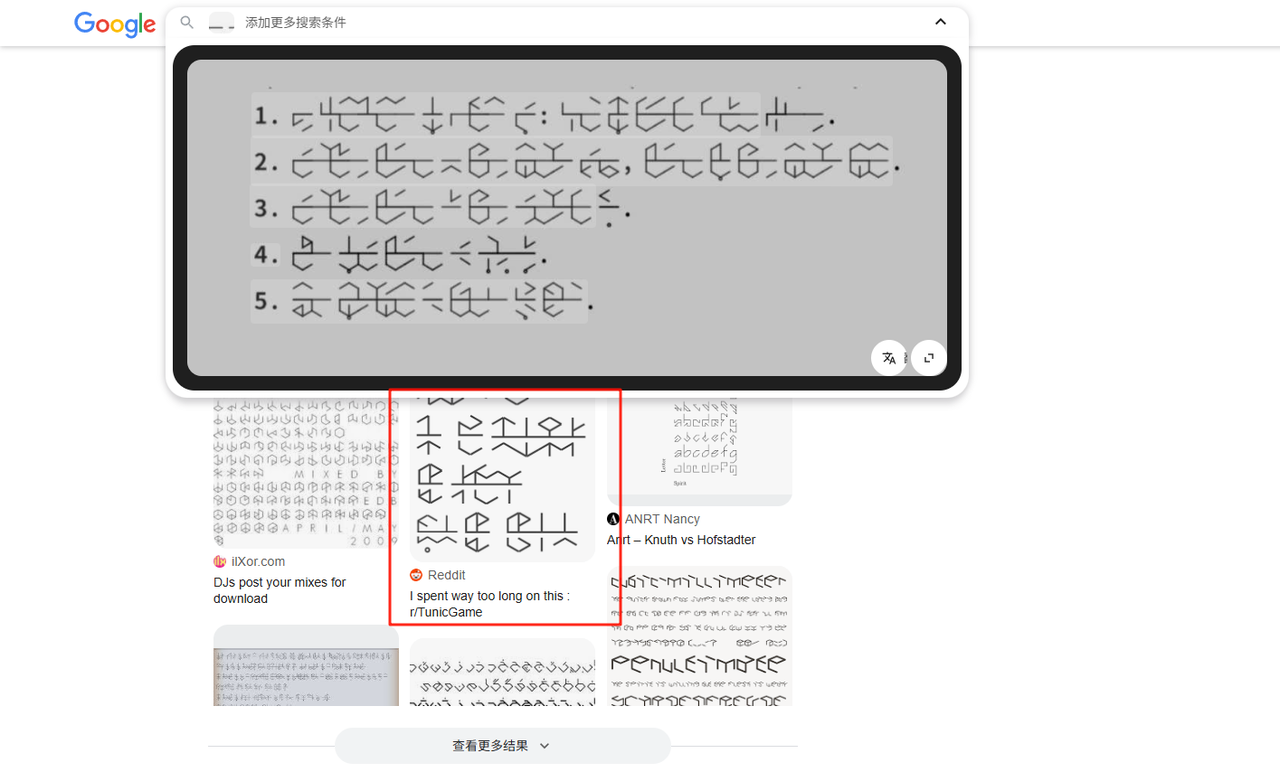
随后,又找到了在b站上的一个视频,https://www.bilibili.com/video/BV1n541117Pi/,里面详细介绍了这种文字如何翻译成英文单词,这种文字将单词的音标划分为元音和辅音后,然后通过外圆内辅的构造方式拼凑出英文单词(红线为外,蓝线为内)
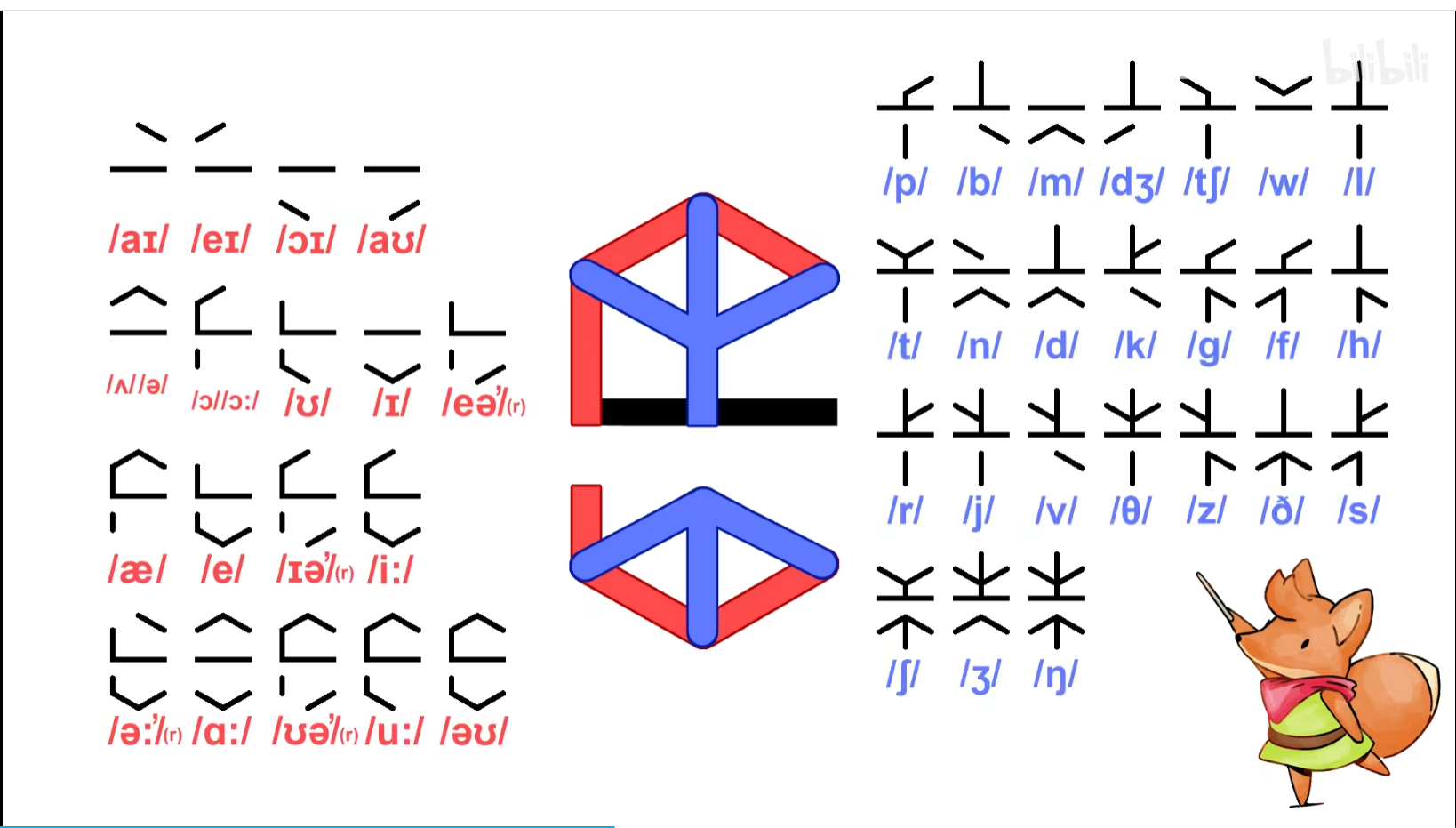
然而,到这里本以为可以通过直接的对照去破译图片里的文字,结果发现完全不行,题目中的文字跟原版的规则完全对不上,不难猜到作者对文字进行了魔改。
这时候就需要用到前面给的提示:IGN Review,简单搜一下可以发现ign中对tunic这个游戏的官方测评只有一个,链接如下
https://www.ign.com/articles/tunic-review-xbox-pc-steam
进去后,如果有留意题目给的内容,会发现第一段文字其实有一些奇妙的熟悉感
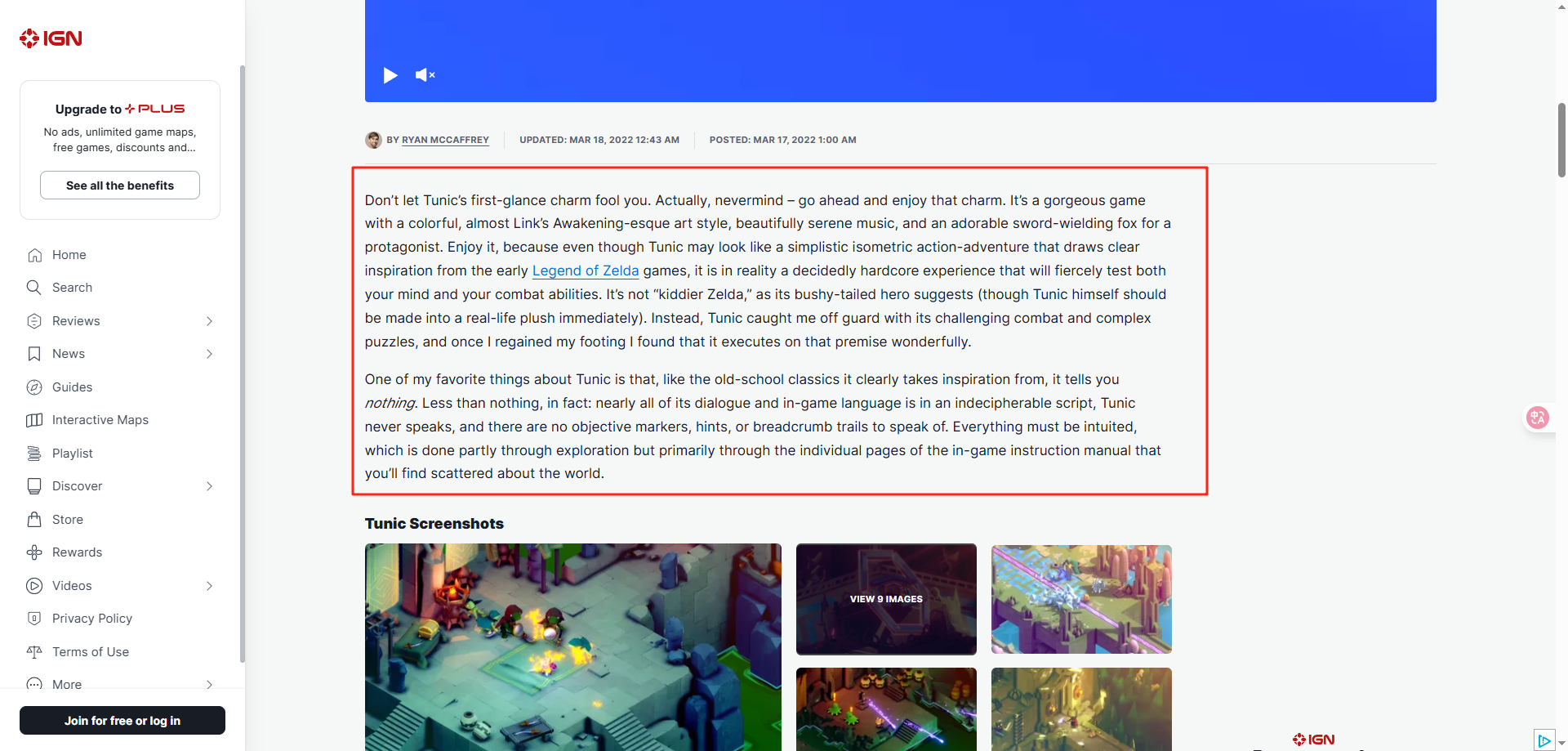
简单比对一下,可以明显的发现两边的符号是能很好的对上的,也就是说——图片中的密文所对应的明文的内容就是ign评测的第一段
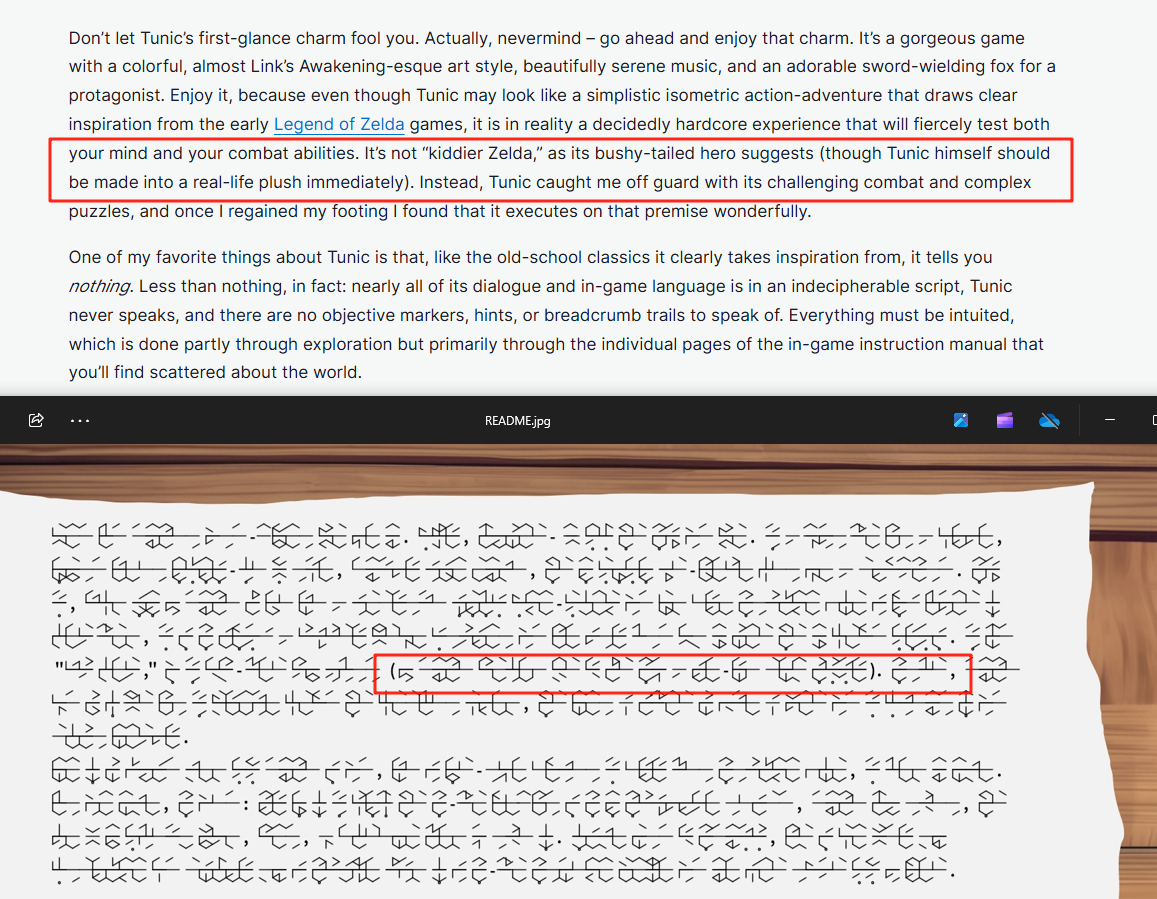
至此有了重大的突破,既然有了明确的明文和对应密文,那我们就可以去进行逐一的比对后,从而破译别的密文(图片下面还有五行密文)
开始破译:
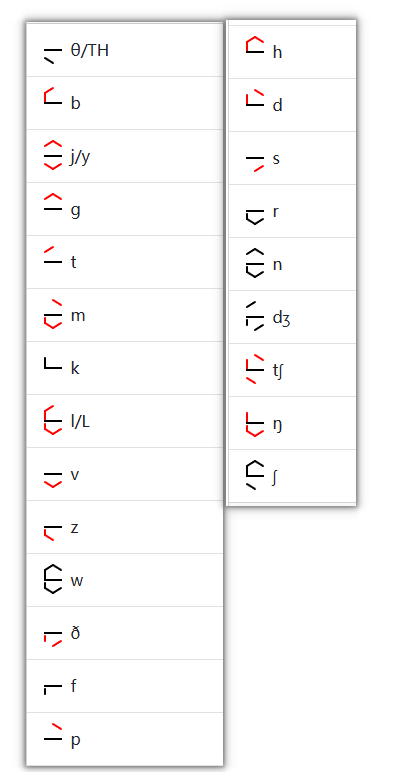
首先考虑的是出题人在魔改的时候是否带有某些规律,比如说对文字进行了反转,异或等处理,通过比对后发现并没有什么可以便于我们破译的规律,唯独只有一个规律,那就是作者把原本外圆内辅的构造方式改成了外辅内圆(byd破译的时候还得把外改内 内改外 工作量又大了)
接着开始进行手搓,借由https://lunar.exchange/tunic-decoder/ 这个web进行辅助,最终成功对新的码表在基于已知密明文的情况下,完成了最大程度的破译(如果有出错的部分可以及时跟我反馈):
首先是辅音部分:
其次是元音部分:
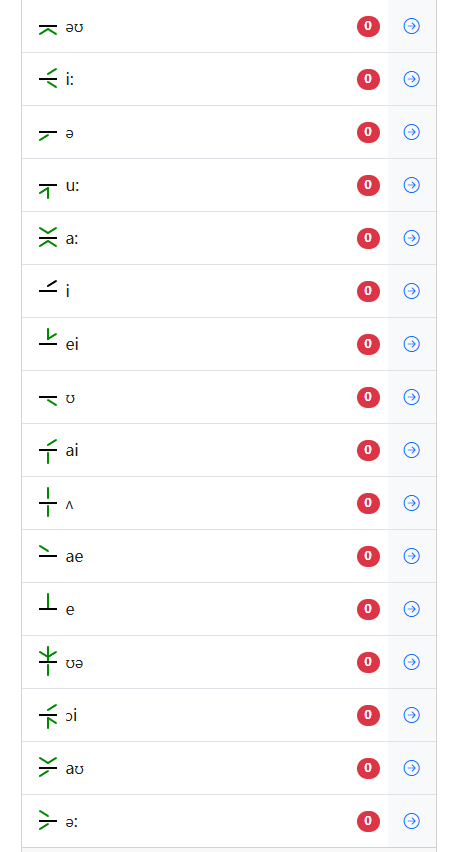
要注意给出的原文中有个别的音标好像存在丢失,但不影响我们进行后面的破译工作
码表建立后,转化成对应的单词即可,过程省略了,想尝试的朋友可以自己试试)
最终破译出来的内容大致如下,简单处理一下即可得到正确的flag
the content of flag is: come on little brave fox
replace letter o with number zero, letter l with number one
replace letter a with symbol at
make every letter e uppercase
use underline to link each word
Please Sign In
知识点省流
很简单的ai向量反演
WP
附件给了一个dockerfile、一个json还有一个服务端源码
源码如下,简单分析一下可以发现当用户传入的图片与预存的图片的均方误差低于0.000005时,就检测通过并回复flag
import uvicorn
import torch
import json
import os
from fastapi import FastAPI, File, UploadFile
from PIL import Image
from torchvision import transforms
from torchvision.models import shufflenet_v2_x1_0, ShuffleNet_V2_X1_0_Weights
feature_extractor = shufflenet_v2_x1_0(weights=ShuffleNet_V2_X1_0_Weights.IMAGENET1K_V1)
feature_extractor.fc = torch.nn.Identity()
feature_extractor.eval()
weights = ShuffleNet_V2_X1_0_Weights.IMAGENET1K_V1
transform = transforms.Compose([
transforms.ToTensor(),
])
if not os.path.exists("embedding.json"):
user_image = Image.open("user_image.jpg").convert("RGB")
user_image = transform(user_image).unsqueeze(0)
with torch.no_grad():
user_embedding = feature_extractor(user_image)[0]
with open("embedding.json", "w") as f:
json.dump(user_embedding.tolist(), f)
user_embedding = json.load(open("embedding.json", "r"))
user_embedding = torch.tensor(user_embedding, dtype=torch.float32)
user_embedding = user_embedding.unsqueeze(0)
app = FastAPI()
@app.post("/signin/")
async def signin(file: UploadFile = File(...)):
submit_image = Image.open(file.file).convert("RGB")
submit_image = transform(submit_image).unsqueeze(0)
with torch.no_grad():
submit_embedding = feature_extractor(submit_image)[0]
diff = torch.mean((user_embedding - submit_embedding) ** 2)
result = {
"status": "L3HCTF{test_flag}" if diff.item() < 5e-6 else "failure"
}
return result
@app.get("/")
async def root():
return {"message": "Welcome to the Face Recognition API!"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
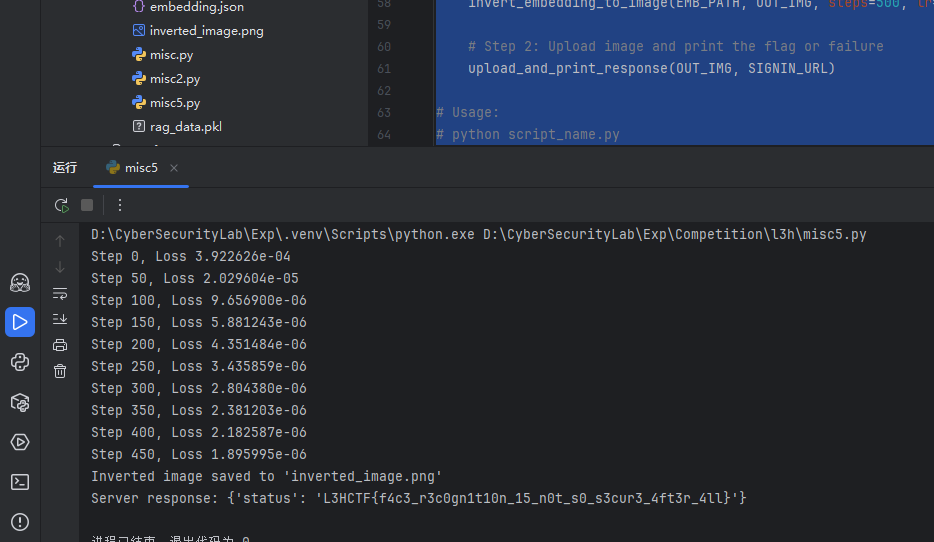
因为条件不复杂,直接让gpt写个脚本就出了
import torch
from torchvision import transforms
from torchvision.models import shufflenet_v2_x1_0, ShuffleNet_V2_X1_0_Weights
from PIL import Image
import json
import requests
import os
def invert_embedding_to_image(embedding_path, output_path, steps=500, lr=0.1):
# Load model
model = shufflenet_v2_x1_0(weights=ShuffleNet_V2_X1_0_Weights.IMAGENET1K_V1)
model.fc = torch.nn.Identity()
model.eval()
# Load target embedding
with open(embedding_path, 'r') as f:
target_emb = torch.tensor(json.load(f), dtype=torch.float32)
# Initialize trainable image tensor (noise)
img = torch.randn(1, 3, 224, 224, requires_grad=True)
optimizer = torch.optim.Adam([img], lr=lr)
for step in range(steps):
optimizer.zero_grad()
# Sigmoid to bound pixels between 0 and 1
clipped = img.sigmoid()
emb = model(clipped)[0]
loss = torch.nn.functional.mse_loss(emb, target_emb)
loss.backward()
optimizer.step()
if step % 50 == 0:
print(f'Step {step}, Loss {loss.item():.6e}')
# Convert to image and save
result = (clipped.detach().squeeze().permute(1, 2, 0).cpu().numpy() * 255).astype('uint8')
inv_image = Image.fromarray(result)
inv_image.save(output_path)
print(f"Inverted image saved to '{output_path}'")
def upload_and_print_response(image_path, server_url):
if not os.path.exists(image_path):
print(f"File '{image_path}' not found.")
return
with open(image_path, 'rb') as f:
files = {'file': f}
response = requests.post(server_url, files=files)
try:
print("Server response:", response.json())
except ValueError:
print("Server response (text):", response.text)
if __name__ == "__main__":
EMB_PATH = 'embedding.json'
OUT_IMG = 'inverted_image.png'
SIGNIN_URL = 'http://1.95.8.146:50001/signin/'
# Step 1: Invert embedding to image
invert_embedding_to_image(EMB_PATH, OUT_IMG, steps=500, lr=0.1)
# Step 2: Upload image and print the flag or failure
upload_and_print_response(OUT_IMG, SIGNIN_URL)
PaperBack
知识点省流
基本算是个小众工具题
WP
下载附件得到一张奇怪的bmp图

但事实上救赎之道就在题目中,有这么一个与题目同名的工具:https://ollydbg.de/Paperbak/
用这个工具打开这个bmp图片后,他会导出一个ws文件
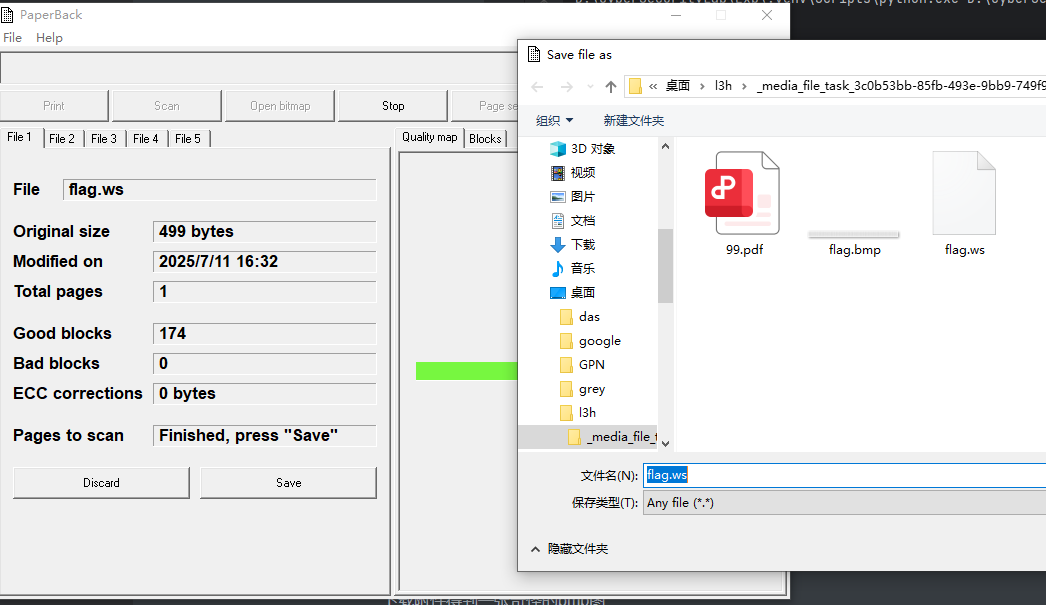
打开文件会发现里面有奇怪的缩进 空格
将所有数据复制到厨子中,对其进行一些简单的处理:将缩进空格转为hex值后,再将20替换成0,09替换成1,再删掉没用的内容(090a)即可得到如下结果
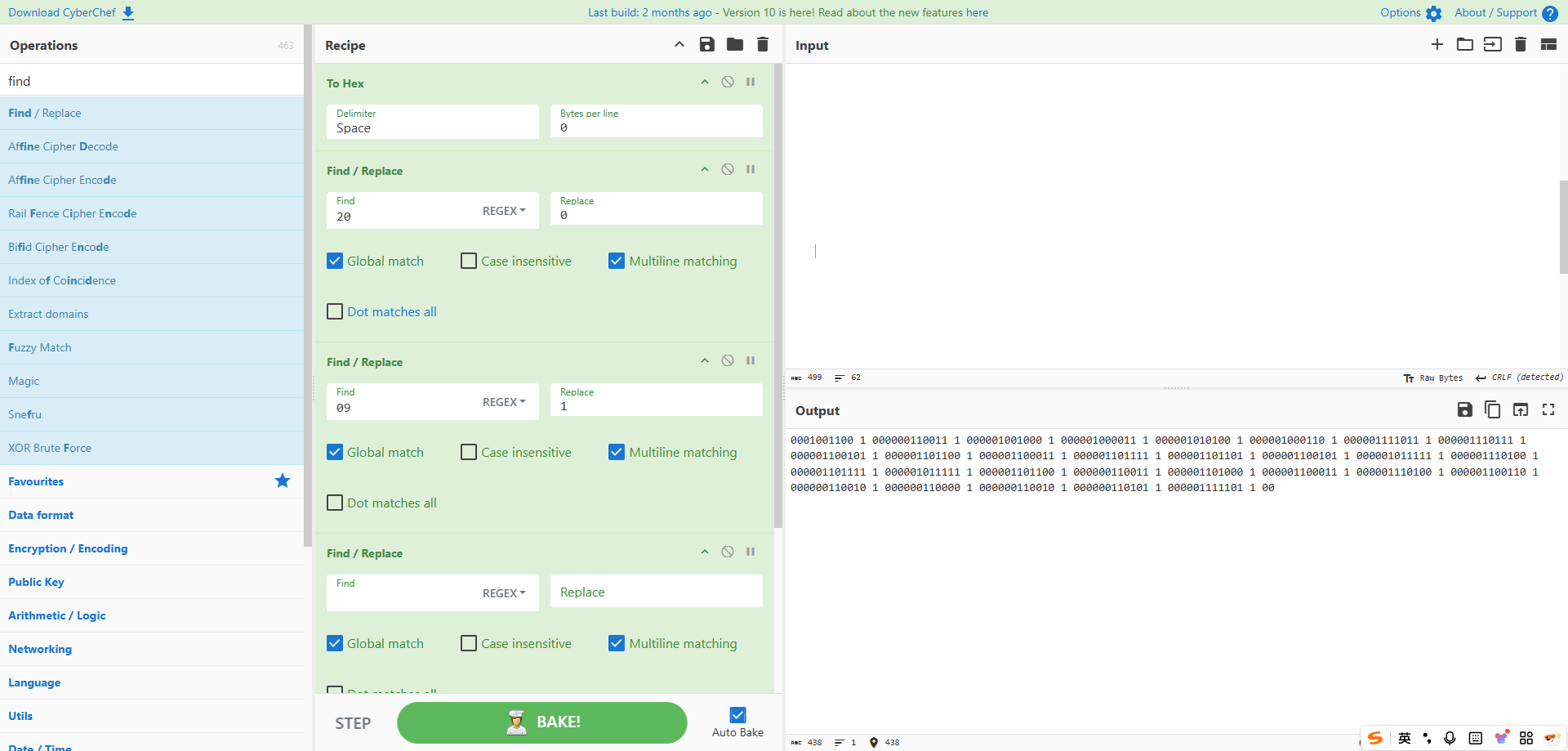
不难看出每段里藏了一个8位的二进制字符串,前面正好能跟L3H的二进制值对应,所以提取出来转换成ascii值即可得到完整flag