第五届红明谷 - MISC - WriteUp
碎碎念
第一次参加这个赛,因为一些原因,组好队了才知道只有web misc 和crypto方向的题,队伍里只有我一个对得上的,最后只能独自奋战了。不过比较好的是红明谷的题目难度还可以,不算难。misc这边全都是脚本题,有对应思路搞个脚本就做出来了(甚至直接gpt)
最后拿了个44名,还不错,下次数字中国积分赛争取能跟队友们冲个决赛qwq
异常行为溯源
知识点省流
本题考查流量取证
WP
用tshark把data.data导出,然后写脚本解码,最后统计哪个ip最多
tshark导出(有很多奇怪的协议导不出来,但其实不影响)
tshark -r network_traffic.pcapng -T fields -e data.data > data.txt
用脚本处理数据
import base64
import json
def hex_to_ascii(file_path, output_path):
try:
with open(file_path, 'r', encoding='utf-8') as infile, open(output_path, 'w', encoding='utf-8') as outfile:
for line in infile:
line = line.strip() # 去除换行符和空格
try:
ascii_text = bytes.fromhex(line).decode('ascii') # hex解码
base64_decoded_text = base64.b64decode(ascii_text).decode('utf-8') # Base64 解码
json_data = json.loads(base64_decoded_text) # 解析JSON数据
if 'msg' in json_data:
base64_encoded_msg = json_data['msg'] # 提取msg字段
final_decoded_msg = base64.b64decode(base64_encoded_msg).decode('utf-8') # 再次Base64解码
outfile.write(final_decoded_msg + '\n')
except (ValueError, base64.binascii.Error, UnicodeDecodeError, json.JSONDecodeError):
print(f"无法解码的行: {line}")
except FileNotFoundError:
print("文件未找到,请检查路径是否正确!")
# 示例用法
input_file = "data.txt" # 你的hex编码数据文件
output_file = "decoded_output.txt" # 解码后的输出文件
hex_to_ascii(input_file, output_file)
print("解码完成,结果已保存到", output_file)
导入linux,统计ip出现次数,最多那个就是flag
cat decoded_output.txt | awk '{print$1}' | sort | uniq -c | sort -nr | more
数据校验
知识点省流
本题考查写脚本
WP

要保证每一条都是合规,要注意ip也得检验(要符合xxx.xxx.xxx.xxx,xxx不能大于255)
import csv
import hashlib
import re
import ecdsa
import base64
import os
def md5_hash(value):
return hashlib.md5(value.encode('utf-8')).hexdigest()
def verify_signature(serial_number, username, signature):
try:
# Ensure the public key file exists based on the serial_number
public_key_file = os.path.join('ecdsa-key', f"{serial_number}.pem")
if not os.path.isfile(public_key_file):
raise FileNotFoundError(f"公钥文件未找到: {public_key_file}")
# Read the public key from the file
with open(public_key_file, 'r') as key_file:
public_key = key_file.read()
verifier = ecdsa.VerifyingKey.from_pem(public_key)
signature_bytes = base64.b64decode(signature)
verifier.verify(signature_bytes, username.encode('utf-8'))
return True
except (ecdsa.BadSignatureError, ValueError, FileNotFoundError) as e:
print(f"验证签名失败: {e}")
return False
def validate_row(index, row):
errors = []
# 校验 UserName 格式
if not re.fullmatch(r'User-\w+', row[1]):
errors.append("UserName 格式错误")
# 校验 UserName_Check
if row[2] != md5_hash(row[1]):
errors.append("UserName_Check 错误")
# 校验 Password 格式
if not re.fullmatch(r'[A-Za-z0-9]+', row[3]):
errors.append("Password 格式错误")
# 校验 Password_Check
if row[4] != md5_hash(row[3]):
errors.append("Password_Check 错误")
# 校验 Signature
if not verify_signature(row[0],row[1], row[6]): # Use Serial_Number for public key lookup
errors.append("Signature 校验失败")
# 校验 IP 格式
ip = row[5]
ip_pattern = r"^(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$"
if not re.match(ip_pattern, ip):
errors.append("IP 格式错误")
if errors:
print(f"第 {index + 1} 行数据不合规: {', '.join(errors)}")
def read_csv(file_path):
with open(file_path, mode='r', encoding='utf-8') as file:
reader = csv.reader(file)
headers = next(reader) # 读取并跳过表头
for index, row in enumerate(reader):
validate_row(index, row)
# 示例调用
csv_file_path = "data.csv" # 请将此路径更改为你的 CSV 文件路径
read_csv(csv_file_path)
Strange_Database
知识点省流
本题考查脚本小子,rc4加密,rsa加密 pem私钥解密
WP
500个db文件里的数据都进行了RSA加密,要写脚本解出来
同时每个pem文件都用openssl加密过,也要逐一解密
看了一下key里面的私钥,都是加密过的,数量太多只能用脚本解了
#!/usr/bin/env python3
import glob
import os
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.backends import default_backend
def decrypt_pem_file(filename):
# 读取加密的 PEM 文件
with open(filename, "rb") as f:
encrypted_key = f.read()
# 从文件名中提取密码:取最后一个 '-' 后面的部分,去除扩展名
base_name = os.path.basename(filename)
password_with_ext = base_name.split('-')[-1]
password = password_with_ext.rsplit('.', 1)[0]
try:
# 加载并解密 PEM 文件,password 需要为字节串
private_key = serialization.load_pem_private_key(
encrypted_key,
password=password.encode(),
backend=default_backend()
)
except Exception as e:
print(f"文件 {filename} 解密失败:{e}")
return None
# 将解密后的私钥转换为不加密的 PEM 格式
try:
decrypted_key = private_key.private_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PrivateFormat.TraditionalOpenSSL,
encryption_algorithm=serialization.NoEncryption()
)
except Exception as e:
print(f"序列化私钥时出错 {filename}: {e}")
return None
return decrypted_key
def batch_decrypt():
output_dir = "decrypted"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历当前目录下所有符合 OAEP-*.pem 格式的文件
pem_files = glob.glob("key/OAEP-*.pem")
if not pem_files:
print("未找到符合格式的 PEM 文件。")
return
counter = 0 # Initialize the counter
for pem_file in pem_files:
print(f"正在解密文件 {pem_file} ...")
decrypted_key = decrypt_pem_file(pem_file)
if decrypted_key:
output_file = os.path.join(output_dir, f"OAEP-{counter}.pem") # Use the counter for the output file name
with open(output_file, "wb") as f:
f.write(decrypted_key)
print(f"文件 {pem_file} 解密成功,输出文件为 {output_file}\n")
counter += 1 # Increment the counter for the next file
else:
print(f"文件 {pem_file} 解密失败。\n")
if __name__ == "__main__":
batch_decrypt()
解完再读取db文件再去解密db里的数据
import glob
import os
import sqlite3
from time import sleep
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_OAEP
import base64
def read_db_data(db_file):
# 连接到 SQLite 数据库
conn = sqlite3.connect(db_file)
# 创建一个游标对象,用于执行 SQL 查询
cursor = conn.cursor()
try:
# 执行查询,获取所有表的名字
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
if tables:
table_name = tables[0][0] # 假设我们选择第一个表
# 执行查询,读取表中的数据
cursor.execute(f"SELECT * FROM {table_name};")
rows = cursor.fetchall()
decoded_data = [] # 用于存储所有解码的数据
# 假设数据在第四列(索引为3)
for row in rows:
# 将解码后的数据加入列表
decoded_data.append(base64.b64decode(row[0]))
# print(decoded_data)
return decoded_data # 返回所有解码后的数据
except sqlite3.Error as e:
print(f"Error reading the database: {e}")
finally:
# 关闭连接
conn.close()
def rsa_decrypt(private_key_path, ciphertext):
# 从文件读取私钥
with open(private_key_path, 'rb') as f:
private_key_pem = f.read()
private_key = RSA.import_key(private_key_pem)
cipher = PKCS1_OAEP.new(private_key)
# 解密
decrypted_data = cipher.decrypt(ciphertext)
return decrypted_data.decode()
def process_db_and_pem_files(db_directory, pem_directory, output_file):
"""处理所有的DB和PEM文件并将解密结果保存到一个txt文件中"""
with open(output_file, 'wb') as out_file:
for i in range(500):
# DB文件路径
db_file_path = os.path.join(db_directory, f'database-{i}.db')
# 查找匹配的PEM文件,格式为 'OAEP-i-xxxxxx-decrypted'
pem_file_pattern = os.path.join(pem_directory, f'OAEP-{i}-*.pem')
pem_files = glob.glob(pem_file_pattern)
if not pem_files:
print(f"没有找到匹配的PEM文件: {pem_file_pattern}")
continue
# 选择找到的第一个PEM文件
pem_file_path = pem_files[0]
# 确保DB文件和PEM文件都存在
if not os.path.exists(db_file_path) or not os.path.exists(pem_file_path):
print(f"文件不存在: {db_file_path} 或 {pem_file_path}")
continue
# 读取DB文件的加密数据
encrypted_data = read_db_data(db_file_path)
# 解密数据
try:
for t in range(20):
decrypted_data = rsa_decrypt(pem_file_path, encrypted_data[t])
# print(decrypted_data)
# 将解密后的数据追加到输出文件
out_file.write(decrypted_data.encode()) # 将字符串转换为字节写入文件
out_file.write(b'\n') # 可以加一个换行符分隔每个文件的内容
except Exception as e:
print(f"解密文件 {db_file_path} 时发生错误: {e}")
if __name__ == '__main__':
db_directory = 'database' # DB文件所在的目录
pem_directory = 'decrypted' # PEM文件所在的目录
output_file = 'output/decrypted_data3.txt' # 总的解密结果保存文件
process_db_and_pem_files(db_directory, pem_directory, output_file)
将其中一db文件用在线db查看网站查看一下可以看到有如下字段
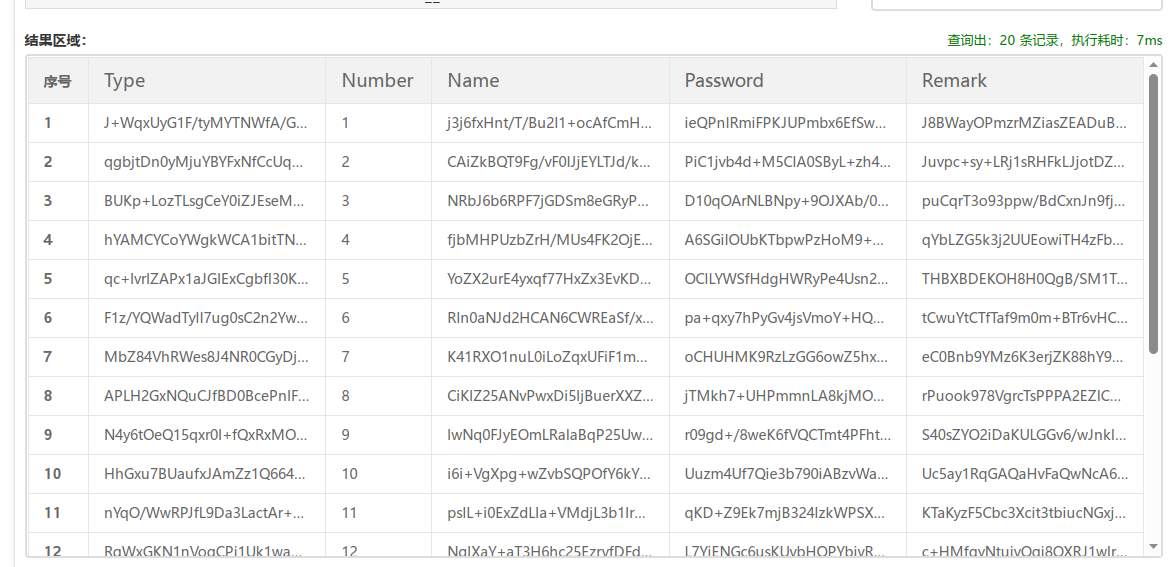
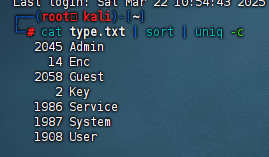
解密完所有数据后导出Type一列,再简单处理一下会发现里面有Enc和Key两个比较特别的用户,不难看出一个对应密文一个对应密钥
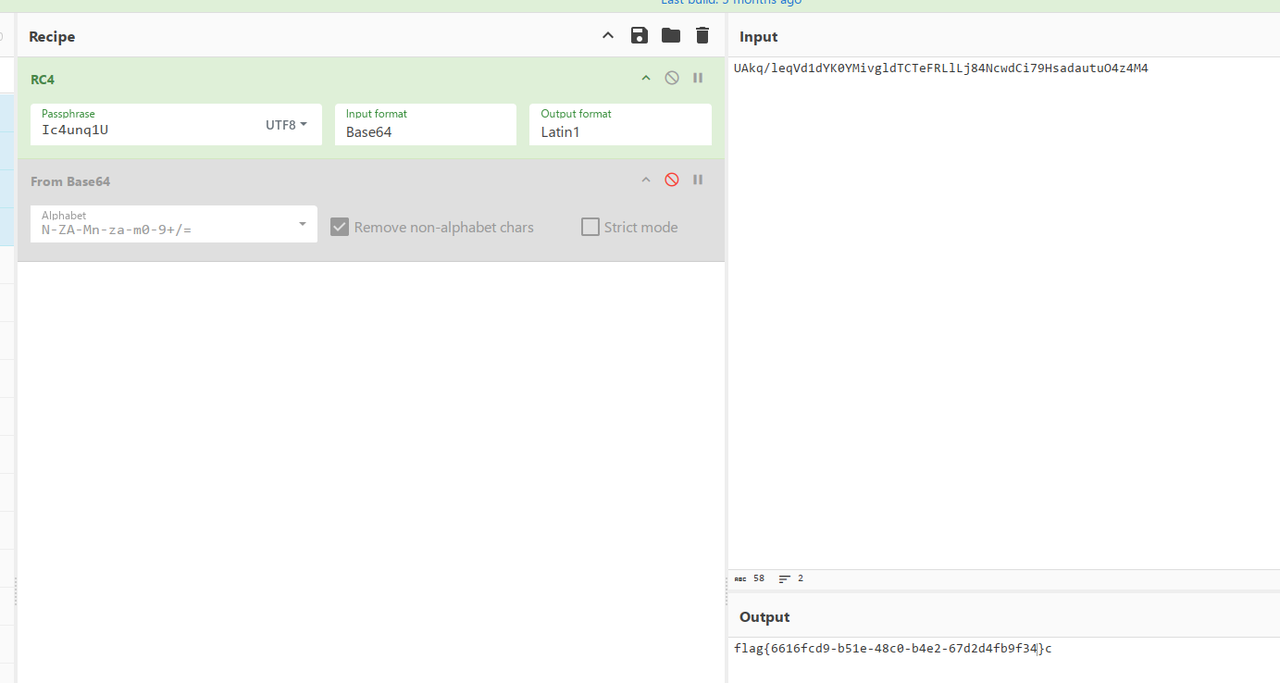
猜测是某种带Key的加密,分别将他们其对应行号的Remark值拼接,最后用RC4解密即可