
2025强网杯 - Misc - WriteUp
碎碎念
待到秋光澄澈,菊吐金英相候,
迟逾时序已久,待至吉日重逢。
……
吉时已到
这次比赛对我来说可以说是强运附体了,在不懈努力下,最终也是砍下了两个Misc一血,该做的misc也都做了(除了最后黑珍珠实在是没机会看了要去给新生培训了,不然我直接就是一个以我残躯化烈火)
这次Misc方向的题目我感觉难度上还不错,有的题目出的挺好的,但也存在个别题有点太脑洞了(没有针对出题人的意ORZ),我一直以来对Misc的看法都是——不断进化,不断学习,干中学学中干,每一次比赛都是一次学习的机会(因为每次比赛都有新的东西,这就是我们Misc),在这次强网杯中,我也收获了很多,学到了很多新的东西,也打的很爽。
……(原本这里还想说点什么,不过想了想还是算了,等年度总结再发吧)
“开始时捱一些苦,栽种绝处的花”,就目前来看,我的所知所学还是太过浅薄了,以此作为转折,继续努力吧
与君共勉,最高峰见 —— 2hi5hu
新编:
“最后一舞”
Personal Vault(一血)
知识点省流
内存取证但非预期
WP
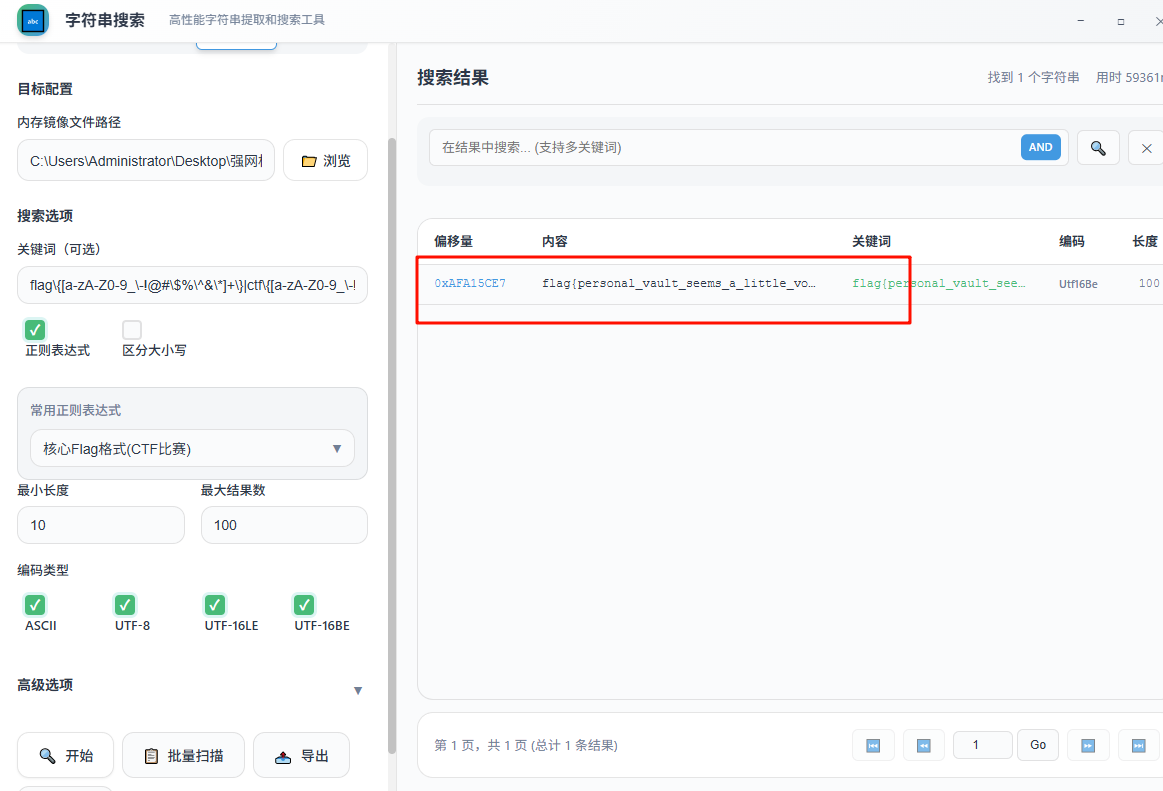
一血,没想太多,直接拿lovelymem luxe搜了一波flag,直接非了
The_Interrogation_Room
知识点省流
海明距离什么的 但是ai梭哈了
WP
复盘来看,这题的解题过程其实非常的搞笑()
附件叽里咕噜说的啥听不懂,大概就是要提问17轮,其中有两轮是说谎的,根据信息推出正确的数据,要连续猜对25轮
这题目的解题数涨的很快,所以我们都大概能猜到是ai能梭的,但是却一直没梭出来
但毕竟那么多解,而且这类题目ai梭哈的概率很大,所以我也没太放心上,打算歇一会再做
结果就有了下面这一幕,当时题解数已经多到可怕了,一怒之下问ai梭了

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
solve_interrogation_coded.py
Robust automated client that constructs a 17-query error-correcting measurement
set (XOR-based), so that up to 2 erroneous answers can be corrected reliably.
Usage: python3 solve_interrogation_coded.py
"""
import socket, hashlib, random, re, time, itertools
from itertools import product
HOST = "39.106.57.152"
PORT = 22667
TIMEOUT = 12
ALPHABET = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
# ---------------- I/O helpers ----------------
def recv_all(sock, timeout=0.5):
sock.settimeout(timeout)
out = b""
try:
while True:
chunk = sock.recv(4096)
if not chunk:
break
out += chunk
if len(chunk) < 4096:
break
except socket.timeout:
pass
except Exception:
pass
try:
return out.decode(errors='replace')
except:
return out.decode('utf-8','replace')
def recv_until(sock, marker, timeout=8):
end = time.time() + timeout
data = ""
while time.time() < end:
data += recv_all(sock, timeout=0.2)
if marker in data:
return data
return data
def send_line(sock, s):
if isinstance(s, str):
sock.sendall((s + "\n").encode())
else:
sock.sendall(s + b"\n")
# ---------------- POW ----------------
def parse_pow(text):
m = re.search(r"sha256\(\s*XXXX\s*\+\s*([^\)\s]+)\s*\)\s*==\s*([0-9a-fA-F]{64,})", text)
if not m:
return None, None
return m.group(1).strip().strip("{}"), m.group(2).strip()
def brute_prefix(suffix, target_hex):
sfx = suffix.encode()
# randomized attempts first
for _ in range(200000):
cand = ''.join(random.choice(ALPHABET) for _ in range(4)).encode()
if hashlib.sha256(cand + sfx).hexdigest() == target_hex:
return cand.decode()
# deterministic fallback
for a in ALPHABET:
for b in ALPHABET:
for c in ALPHABET:
for d in ALPHABET:
cand = (a+b+c+d).encode()
if hashlib.sha256(cand + sfx).hexdigest() == target_hex:
return cand.decode()
return None
# ---------------- build XOR expression (white-list-safe) ----------------
def fmt_token(tok):
# tokens like "( S0 == 1 )" already spacing-safe; we ensure spacing around parens and == later
return tok
def xor2_expr(a_expr, b_expr):
# XOR(a,b) = (a and not b) or (not a and b)
# but 'not' isn't in whitelist; use (a==1 and b==0) or (a==0 and b==1)
return "( ( " + a_expr + " and " + "( " + b_expr + " ) == 0 ) or ( ( " + a_expr + " ) == 0 and " + b_expr + " ) )"
def build_xor_expr(indices):
"""
indices: list of bit indices [0..7] to XOR together
returns string expression using allowed tokens
implement by folding pairwise XOR
base var expression for bit i: ( S{i} == 1 )
For a single index, return "( S{i} == 1 )"
"""
assert len(indices) >= 1
def var(i):
return f"( S{i} == 1 )"
exprs = [var(i) for i in indices]
# fold using xor2_expr
cur = exprs[0]
for e in exprs[1:]:
# xor2_expr expects boolean-like strings; but it uses "== 0" comparisons
# ensure inside expressions are parenthesized
cur = "( ( " + cur + " and ( " + e + " ) == 0 ) or ( ( " + cur + " ) == 0 and " + e + " ) )"
# clean up double spaces
return re.sub(r"\s+", " ", cur).strip()
# ---------------- search for good generator matrix G (8 x 17) ----------------
def weight(v):
return sum(1 for x in v if x)
def code_min_distance(G_cols):
# G_cols: list of 17 column vectors each length 8 bits (0/1)
# compute all codewords s*G (mod 2) for s in 1..255 and return minimum weight
minw = None
# For speed, precompute columns as ints bitpacked
col_ints = []
for col in G_cols:
val = 0
for i,b in enumerate(col):
if b:
val |= (1<<i)
col_ints.append(val)
# enumerate nonzero s in 1..255
for s in range(1, 1<<8):
# compute codeword bits across 17 columns: bit j = parity(popcount(col_ints[j] & s))
cw_weight = 0
for c in col_ints:
bits = bin(c & s).count("1")
b = bits & 1
cw_weight += b
# early cutoff
if minw is not None and cw_weight >= minw:
break
if cw_weight == 0:
continue
if minw is None or cw_weight < minw:
minw = cw_weight
if minw == 1:
return 1
return minw if minw is not None else 0
def find_good_G(max_tries=20000):
# return G_cols: list of 17 columns each a list of 8 bits (0/1), with min distance >=5
tries = 0
while tries < max_tries:
tries += 1
# generate random full-rank generator matrix: 8x17 (we create 17 columns length 8)
# ensure rank 8 by ensuring first 8 columns form invertible matrix - simpler: construct by starting with identity cols then add random
cols = []
# put identity columns first
for i in range(8):
col = [0]*8
col[i] = 1
cols.append(col)
# remaining 9 random nonzero columns
for _ in range(9):
col = [random.choice([0,1]) for _ in range(8)]
# avoid all zero column
if sum(col) == 0:
col[random.randrange(8)] = 1
cols.append(col)
# compute min distance
dmin = code_min_distance(cols)
if dmin >= 5:
print(f"[+] Found G with dmin={dmin} after {tries} tries")
return cols
# else shuffle and try small mutation occasionally
if tries % 500 == 0:
pass
raise RuntimeError("failed to find good G in given tries")
# ---------------- build queries from G ----------------
def build_queries_from_G(G_cols):
# For each column (list of 8 bits) produce XOR expression of indices where bit==1
queries = []
for col in G_cols:
inds = [i for i,b in enumerate(col) if b]
if not inds:
# column zero shouldn't happen; use constant 0 expression
q = "( 0 == 1 )"
elif len(inds) == 1:
q = f"( S{inds[0]} == 1 )"
else:
q = build_xor_expr(inds)
# normalize spaces to avoid smirk
q = re.sub(r"\s+", " ", q).strip()
queries.append(q)
return queries
# ---------------- helper to encode secret by G ----------------
def encode_by_G(s_tuple, G_cols):
# s_tuple length 8 of 0/1 ints
code = []
for col in G_cols:
# parity of dot product s . col
v = sum(s_tuple[i] & col[i] for i in range(8)) & 1
code.append(bool(v))
return code
# ---------------- main interaction using coded queries ----------------
def run_coded(attempts_find_G=5000):
random.seed() # unpredictable per run
print("[*] Searching for good generator matrix G (this runs locally)...")
G_cols = find_good_G(max_tries=attempts_find_G)
queries = build_queries_from_G(G_cols)
print("[*] Using generated queries (17):")
for i,q in enumerate(queries,1):
print(f"{i:02d}: {q}")
# now network interaction (POW -> send queries -> decode -> submit) - follows same interaction style
sock = socket.create_connection((HOST, PORT), timeout=TIMEOUT)
sock.settimeout(1.0)
try:
banner = recv_until(sock, "Give me XXXX:", timeout=12)
if "sha256" in banner:
suffix, hexd = parse_pow(banner)
if not suffix or not hexd:
banner += recv_all(sock, timeout=0.5)
suffix, hexd = parse_pow(banner)
if not suffix or not hexd:
print("[-] cannot parse POW")
return False
if "Give me" not in banner:
banner += recv_until(sock, "Give me XXXX:", timeout=4)
print("[*] POW suffix:", suffix, "target:", hexd)
prefix = brute_prefix(suffix, hexd)
if not prefix:
print("[-] POW failed")
return False
print("[+] POW solved:", prefix)
send_line(sock, prefix)
intro = recv_until(sock, "Ask your question:", timeout=12)
print(intro.strip())
_ = recv_all(sock, timeout=0.1)
rounds = 0
while True:
rounds += 1
print(f"[*] Round {rounds}")
answers = []
# send our designed queries sequentially
for i,q in enumerate(queries, start=1):
print(f"[>] Q{i:02d}: {q}")
send_line(sock, q)
resp = recv_until(sock, "Prisoner's response:", timeout=8)
resp += recv_all(sock, timeout=0.25)
print(resp.strip())
if "smirks" in resp or "refuse to answer" in resp:
print("[-] server refused phrasing. aborting")
return False
tail = resp.split("Prisoner's response:",1)[-1]
# parse boolean
if "True" in tail and "False" not in tail:
val = True
elif "False" in tail and "True" not in tail:
val = False
elif "True" in tail:
val = True
elif "False" in tail:
val = False
else:
val = False
answers.append(bool(val))
time.sleep(0.01)
# decode: find s in 256 such that Hamming distance between encode_by_G(s) and answers <= 2
best = None
best_hd = 999
cands = []
for s in product([0,1], repeat=8):
code = encode_by_G(s, G_cols)
hd = sum(int(code[i]) != int(answers[i]) for i in range(17))
if hd < best_hd:
best_hd = hd
cands = [s]
elif hd == best_hd:
cands.append(s)
print(f"[*] best_hd={best_hd} candidate_count={len(cands)}")
if best_hd <= 2 and len(cands) >= 1:
# pick unique if single, else majority among candidates
if len(cands) == 1:
guess = cands[0]
else:
# majority vote across candidate bits
counts = [0]*8
for c in cands:
for k,b in enumerate(c):
counts[k] += b
guess = tuple(1 if counts[k]*2 >= len(cands) else 0 for k in range(8))
else:
# fallback: try brute-force search flipping up to 2 bits in answers (shouldn't be necessary)
found = False
for flip_idxs in itertools.combinations(range(17), 0 + 1 + 2):
# try flipping these and see if simple decode by taking first 8 entries yields consistent s
alt = answers[:]
for fi in flip_idxs:
alt[fi] = not alt[fi]
# derive candidate s from first 8 alt bits by decoding linear system? but we used generator form: columns include identity first, so first 8 columns were identity in our G construction -> we can map s directly
# our find_good_G constructed first 8 columns as identity, so alt[0..7] directly are s bits
cand_s = tuple(1 if alt[k] else 0 for k in range(8))
code = encode_by_G(cand_s, G_cols)
if all(bool(code[i]) == bool(alt[i]) for i in range(17)):
guess = cand_s
found = True
break
if not found:
# last fallback: choose minimal hd candidate
guess = cands[0] if cands else tuple(0 for _ in range(8))
print("[*] submit guess:", guess)
send_line(sock, " ".join(str(int(x)) for x in guess))
out = recv_until(sock, "", timeout=2)
out += recv_all(sock, timeout=0.6)
print(out.strip())
if "confesses" in out or "flag" in out.lower() or "you win" in out.lower():
print("[+] success final output:")
print(out)
return True
if "fell for my deception" in out or "disciplinary action" in out:
print("[-] failed this round")
return False
time.sleep(0.1)
except Exception as e:
print("Exception:", e)
try: sock.close()
except: pass
return False
finally:
try: sock.close()
except: pass
if __name__ == "__main__":
random.seed()
try:
ok = run_coded(attempts_find_G=8000)
if not ok:
print("[-] finished without success")
except Exception as e:
print("Exception outer:", e)
过程非常稳定,我发现让ai解题的时候让他去找巧妙的解法很容易出(这也是一种提问的技巧吧,之前有些密码题也能这么问出来)
谍影重重 6.0
知识点省流
rtp流量数据分析 音频转译 历史猜谜
WP
流量分析+妙妙历史猜谜(靠北)
打开题目是一个700多m的流量包,要吓尿了
进去看到全是udp流量,前期绕了很多圈子,特别是看到了个manolito协议,后面反应过来是ws自己误识别的
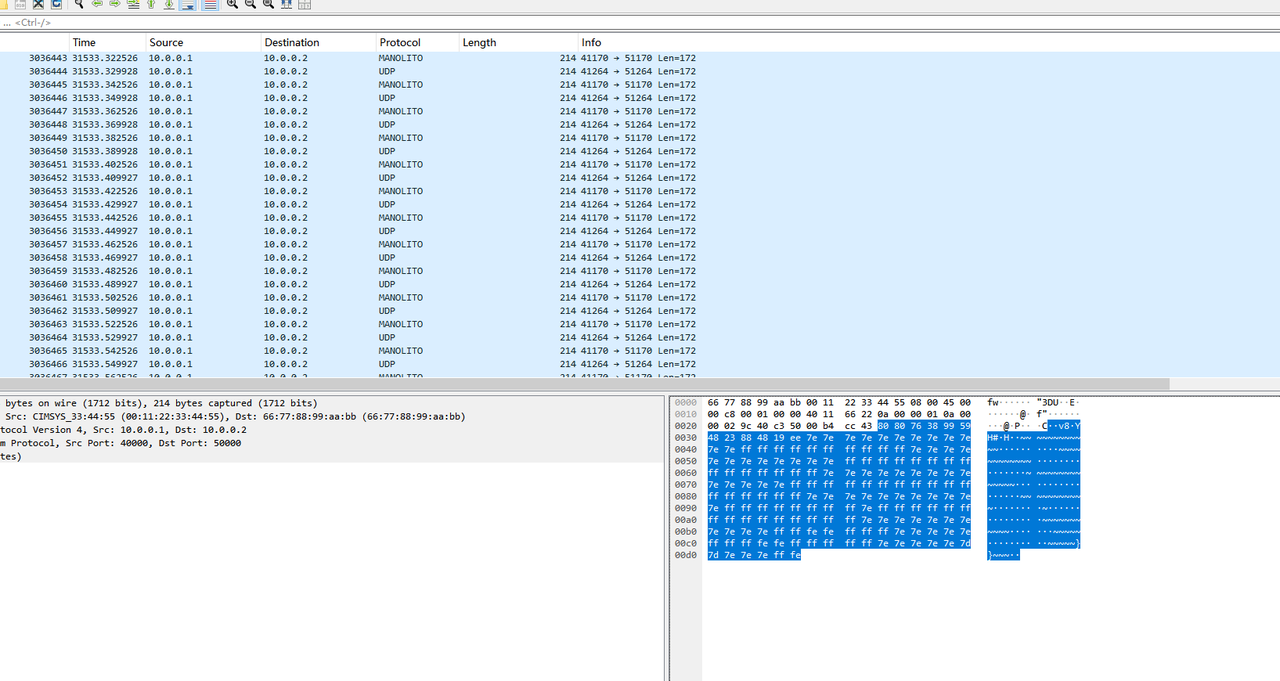
实际上这个udp流量就是rtp数据(看他的数据格式跟之前wm那个voice hacker的流量数据简直一模一样),所以要将他们的音频提取出来,但是简单过了一下发现有1300个端口,每个端口对应一条语音,而且流量包太大了,全部用ws根本不现实,所以要用脚本,之前做voice_hacker有过脚本,在那基础上让ai优化升级了一下
主要调整点在于原音频声音很小,而且有很多空白的地方,所以对提取的音频音量加大了,而且还去掉了空白的部分
然后呢实际上1300个端口,每个端口都有2段数据,就是两段不同的音频,写脚本提取的时候要将重复的区分开,我让ai把他们放在了两个文件夹,然后将同一个目录中的音频按端口顺序合并为一个音频
# -*- coding: utf-8 -*-
# extract_pcmu.py
# 从经典PCAP(小端)中提取 RTP(PCMU, PT=0):
# - 正常音频:丢弃重复包(与原逻辑一致),丢包静音补洞 -> 放大音量 -> 去静音 -> 导出单条 -> 合成总音频
# - 重复包音频:不丢弃重复包,仅把“重复包”按同样逻辑单独拼接为重复音轨 -> 放大音量 -> 去静音 -> 导出单条 -> 合成总音频
# - 生成“非RTP/非PCMU”排查报告 TXT
import os, io, struct, wave, datetime
import numpy as np
from collections import Counter, defaultdict
# ========= 配置 =========
PCAP_PATH = 'Data.pcap' # 你的 pcap 文件 (经典PCAP小端)
OUT_DIR = r"output4" # 正常音频输出目录
DUP_DIR = r"output4_dups" # 重复包音频输出目录
# 合成总音频
COMBINED_MAIN = "combined_by_ports.wav"
COMBINED_DUP = "combined_by_ports_dups.wav"
GAP_SECONDS = 2.0 # 合成段间静音(秒)
SAMPLE_RATE = 8000 # 统一 8kHz, mono, 16-bit
# 音量放大参数
USE_TARGET_PEAK = True # True: 峰值规整化;False: 固定 dB 增益
TARGET_PEAK = 0.98 # 目标峰值(相对 32767),0.98 ≈ -0.18 dBFS
FIXED_GAIN_DB = 6.0 # 若不用目标峰值,则使用固定增益(dB)
CLIP_PROTECT = 0.999 # 额外防削波系数
# 静音剔除(VAD)参数 —— 尽量不影响有声段
FRAME_MS = 20 # 帧长(毫秒)
HOP_MS = 10 # 帧移(毫秒)
SILENCE_THRESHOLD_DBFS = -35.0 # 静音阈值(dBFS)
HYSTERESIS_DB = 3.0 # 滞后带(进入/离开语音的门限差)
MIN_VOICE_MS = 60 # 最短保留语音段(毫秒)
MERGE_GAP_MS = 50 # 两语音段间隙小于该值则合并(毫秒)
LEAD_PAD_MS = 20 # 每段语音前保留的缓冲(毫秒)
TAIL_PAD_MS = 40 # 每段语音后保留的缓冲(毫秒)
# 丢包/重复判断参数
MAX_GAP_PACKETS = 1000 # 小于该缺口视作丢包并静音补洞
FALLBACK_PL_SIZE = 160 # 兜底负载长度(20ms @ 8kHz)
REPORT_NAME = "non_pcmu_report.txt"
# ========================
os.makedirs(OUT_DIR, exist_ok=True)
os.makedirs(DUP_DIR, exist_ok=True)
REPORT_PATH = os.path.join(OUT_DIR, REPORT_NAME)
# --------------- 基础解析 ---------------
def read_pcap_bytes():
if PCAP_PATH and os.path.exists(PCAP_PATH):
with open(PCAP_PATH, "rb") as f:
return f.read()
raise FileNotFoundError(f"找不到 PCAP 路径:{PCAP_PATH}")
def parse_pcap_le(buf: bytes):
# PCAP 全局头 24 字节,小端魔数 0xD4C3B2A1
if len(buf) < 24 or buf[0:4] != b"\xD4\xC3\xB2\xA1":
raise ValueError("不是经典PCAP(小端);请用 Wireshark -> Save As -> pcap(libpcap) 转存再试")
off = 24
while off + 16 <= len(buf):
ts_sec, ts_usec, incl_len, orig_len = struct.unpack("<IIII", buf[off:off+16])
off += 16
pkt = buf[off:off+incl_len]
off += incl_len
yield pkt
def parse_eth(pkt: bytes):
if len(pkt) < 14: return None
dst, src, et = struct.unpack("!6s6sH", pkt[:14])
return et, pkt[14:]
def parse_ipv4(payload: bytes):
if len(payload) < 20: return None
vihl = payload[0]
version = vihl >> 4
ihl = (vihl & 0x0F) * 4
if version != 4 or len(payload) < ihl: return None
total_length = struct.unpack("!H", payload[2:4])[0]
proto = payload[9]
return proto, payload[ihl:total_length]
def parse_udp(seg: bytes):
if len(seg) < 8: return None
srcp, dstp, length, checksum = struct.unpack("!HHHH", seg[:8])
if length < 8 or length > len(seg): return None
return srcp, dstp, seg[8:length]
def parse_rtp(payload: bytes):
# RTP v2 最小 12 字节
if len(payload) < 12: return None
if (payload[0] & 0xC0) != 0x80: return None # Version=2
cc = payload[0] & 0x0F
pt = payload[1] & 0x7F
seq = struct.unpack("!H", payload[2:4])[0]
ts = struct.unpack("!I", payload[4:8])[0]
ssrc = struct.unpack("!I", payload[8:12])[0]
hdr_len = 12 + cc * 4
# 头扩展
if payload[0] & 0x10:
if len(payload) < hdr_len + 4: return None
ext_len = struct.unpack("!H", payload[hdr_len+2:hdr_len+4])[0] * 4
hdr_len += 4 + ext_len
if len(payload) < hdr_len: return None
return {"pt": pt, "seq": seq, "ts": ts, "ssrc": ssrc, "payload": payload[hdr_len:]}
# --------------- G.711 PCMU 解码 ---------------
def mulaw_decode_table():
lut = np.zeros(256, dtype=np.int16)
for i in range(256):
b = i ^ 0xFF # PCMU 8bit 为反码
sign = b & 0x80
exponent = (b >> 4) & 0x07
mantissa = b & 0x0F
sample = (((mantissa << 3) | 132) << exponent) - 132 # 132 = 0x84
if sign:
sample = -sample
lut[i] = np.int16(sample)
return lut
LUT = mulaw_decode_table()
PCMU_SILENCE_BYTE = b'\xFF' # μ-law 静音(解码约为 0)
def decode_mulaw(data: bytes) -> np.ndarray:
u = np.frombuffer(data, dtype=np.uint8)
return LUT[u]
# --------------- 音频处理 ---------------
def apply_gain(pcm: np.ndarray) -> np.ndarray:
"""峰值规整化/固定增益 + 防削波"""
if pcm.size == 0:
return pcm
pcm_f = pcm.astype(np.float32)
if USE_TARGET_PEAK:
peak = float(np.max(np.abs(pcm_f)))
if peak <= 0.0:
return pcm
target_amp = 32767.0 * TARGET_PEAK * CLIP_PROTECT
gain = target_amp / peak
else:
gain = 10.0 ** (FIXED_GAIN_DB / 20.0)
out = pcm_f * gain
out = np.clip(out, -32767.0, 32767.0)
return out.astype(np.int16)
def _rms_dbfs(x: np.ndarray) -> float:
if x.size == 0: return -120.0
x_f = x.astype(np.float32) / 32768.0
rms = np.sqrt(np.mean(x_f * x_f) + 1e-12)
return 20.0 * np.log10(rms + 1e-12)
def remove_silence(pcm: np.ndarray, sr: int = SAMPLE_RATE) -> np.ndarray:
"""能量门限 VAD + 滞后 + 前后包络"""
if pcm.size == 0:
return pcm
frame_len = max(1, int(sr * FRAME_MS / 1000.0))
hop_len = max(1, int(sr * HOP_MS / 1000.0))
frames_db = []
i = 0
while i < len(pcm):
seg = pcm[i:i+frame_len]
frames_db.append(_rms_dbfs(seg))
i += hop_len
frames_db = np.asarray(frames_db, dtype=np.float32)
thr_on = SILENCE_THRESHOLD_DBFS + HYSTERESIS_DB
thr_off = SILENCE_THRESHOLD_DBFS
voiced = np.zeros_like(frames_db, dtype=bool)
state = False
for k, db in enumerate(frames_db):
if not state:
if db >= thr_on: state = True
else:
if db < thr_off: state = False
voiced[k] = state
# 取语音区段
intervals, n, k = [], len(voiced), 0
while k < n:
if voiced[k]:
j = k + 1
while j < n and voiced[j]: j += 1
start = k * hop_len
end = min(len(pcm), (j - 1) * hop_len + frame_len)
intervals.append([start, end])
k = j
else:
k += 1
if not intervals:
return np.array([], dtype=np.int16)
# 合并/最短/前后包络
def ms2samp(ms): return int(sr * ms / 1000.0)
min_len = ms2samp(MIN_VOICE_MS)
mergegap = ms2samp(MERGE_GAP_MS)
lead = ms2samp(LEAD_PAD_MS)
tail = ms2samp(TAIL_PAD_MS)
merged = []
cur_s, cur_e = intervals[0]
for s, e in intervals[1:]:
if s - cur_e <= mergegap:
cur_e = max(cur_e, e)
else:
if cur_e - cur_s >= min_len:
merged.append([cur_s, cur_e])
cur_s, cur_e = s, e
if cur_e - cur_s >= min_len:
merged.append([cur_s, cur_e])
if not merged:
return np.array([], dtype=np.int16)
padded = []
for s, e in merged:
s = max(0, s - lead); e = min(len(pcm), e + tail)
if e > s: padded.append([s, e])
final_intervals = []
cur_s, cur_e = padded[0]
for s, e in padded[1:]:
if s <= cur_e:
cur_e = max(cur_e, e)
else:
final_intervals.append([cur_s, cur_e]); cur_s, cur_e = s, e
final_intervals.append([cur_s, cur_e])
parts = [pcm[s:e] for s, e in final_intervals]
return np.concatenate(parts) if parts else np.array([], dtype=np.int16)
def save_wav(path, pcm, rate=SAMPLE_RATE):
with wave.open(path, "wb") as wf:
wf.setnchannels(1); wf.setsampwidth(2); wf.setframerate(rate)
wf.writeframes(pcm.tobytes())
# --------------- 报告 ---------------
def write_report(report_lines):
with open(REPORT_PATH, "w", encoding="utf-8") as f:
f.write("\n".join(report_lines))
# --------------- 主流程 ---------------
def main():
# 报告统计
non_ipv4_counts = Counter()
non_udp_counts = Counter()
udp_non_rtp = Counter() # (srcp,dstp)
rtp_non_pcmu = Counter() # (srcp,dstp,ssrc,pt)
examples_udp_non_rtp = {}
total_packets = total_ipv4 = total_udp = total_rtp = total_rtp_pcmu = 0
raw = read_pcap_bytes()
streams = {} # key=(srcp,dstp,ssrc) -> [rtp packets]
# 逐包解析 + 统计
for pkt in parse_pcap_le(raw):
total_packets += 1
eth = parse_eth(pkt)
if not eth: continue
etype, l3 = eth
if etype != 0x0800:
non_ipv4_counts[hex(etype)] += 1
continue
total_ipv4 += 1
ip = parse_ipv4(l3)
if not ip: continue
proto, ip_payload = ip
if proto != 17:
non_udp_counts[str(proto)] += 1
continue
total_udp += 1
udp = parse_udp(ip_payload)
if not udp: continue
srcp, dstp, udp_pl = udp
rtp = parse_rtp(udp_pl)
if not rtp:
key = (srcp, dstp)
udp_non_rtp[key] += 1
if key not in examples_udp_non_rtp:
prefix = udp_pl[:16] if udp_pl else b""
examples_udp_non_rtp[key] = prefix.hex(" ")
continue
total_rtp += 1
if rtp["pt"] != 0: # 非 PCMU
key = (srcp, dstp, rtp["ssrc"], rtp["pt"])
rtp_non_pcmu[key] += 1
continue
total_rtp_pcmu += 1
key = (srcp, dstp, rtp["ssrc"])
streams.setdefault(key, []).append(rtp)
if not streams:
print("[!] 没抓到 PT=0(PCMU) 的 RTP。")
# ======== 正常/重复 两路音频构建 ========
out_files_main, out_files_dup = [], []
per_stream_main, per_stream_dup = [], [] # [(key, pcm, path)]
for (srcp, dstp, ssrc), pkts in streams.items():
if not pkts: continue
pkts.sort(key=lambda r: (r["ts"], r["seq"]))
# 统计常见负载长度
try:
size_counts = Counter(len(r["payload"]) for r in pkts)
default_pl_size = size_counts.most_common(1)[0][0]
if default_pl_size <= 0:
default_pl_size = FALLBACK_PL_SIZE
except Exception:
default_pl_size = FALLBACK_PL_SIZE
print(f"\n[+] 流 {srcp}->{dstp} (SSRC={ssrc}) 包数 {len(pkts)},常见负载 {default_pl_size}B")
# 主音轨(丢弃重复包)
main_buf = io.BytesIO(); last_seq_main = None
# 重复音轨(仅由重复包构成,不丢弃重复)
dup_buf = io.BytesIO(); last_seq_dup = None
for r in pkts:
seq = r["seq"]; payload = r["payload"]
# ---------- 主音轨:保持原逻辑(丢弃重复包) ----------
if last_seq_main is None:
last_seq_main = seq
main_buf.write(payload)
else:
if seq == last_seq_main:
# 重复包:主音轨丢弃
pass
else:
exp = (last_seq_main + 1) & 0xFFFF
if seq == exp:
main_buf.write(payload)
last_seq_main = seq
else:
gap = (seq - exp + 65536) % 65536
if gap < MAX_GAP_PACKETS:
main_buf.write(PCMU_SILENCE_BYTE * default_pl_size * gap)
main_buf.write(payload)
last_seq_main = seq
else:
# 大跳变:直接衔接
main_buf.write(payload)
last_seq_main = seq
# ---------- 重复音轨:只收集“重复包内容” ----------
# 规则:当检测到 seq 与“主音轨 last_seq_main 之前值”相同,说明这是重复包;
# 但为避免主/重复交叉状态的问题,我们基于当前包与“上一主包序号”的相等性来定义“重复”:
# 如果与上一主包序号相等(即刚才进入主逻辑时被视作重复),则纳入重复音轨。
# 为实现这一点,我们在进入本循环顶部就先保存一下主轨 last_seq_main_before。
# 简化处理:当主逻辑认定此包为重复(seq == old_last_main),我们就把它写入 dup_buf。
# 这里通过再次判断实现:
# (注意:主轨部分已经把 last_seq_main 更新/保持住了)
# 第二轮再走一遍,标注重复(避免在一次循环里被主轨状态更新影响判定)
last_seq_main = None
for r in pkts:
seq = r["seq"]; payload = r["payload"]
if last_seq_main is None:
last_seq_main = seq
continue
if seq == last_seq_main:
# 命中“重复包” -> 写入重复音轨,并做简单的缺口补偿(相对 dup 序列)
if last_seq_dup is None:
last_seq_dup = seq
dup_buf.write(payload)
else:
# 处理重复音轨的“序列缺口”以保证播放连贯(可选)
exp_dup = (last_seq_dup + 1) & 0xFFFF
if seq == exp_dup:
dup_buf.write(payload)
last_seq_dup = seq
elif seq == last_seq_dup:
# 同一序列的多次重复:直接追加
dup_buf.write(payload)
# last_seq_dup 不变也行;为稳定可设为相同值
last_seq_dup = seq
else:
gap_dup = (seq - exp_dup + 65536) % 65536
if gap_dup < MAX_GAP_PACKETS:
dup_buf.write(PCMU_SILENCE_BYTE * default_pl_size * gap_dup)
dup_buf.write(payload)
last_seq_dup = seq
else:
dup_buf.write(payload)
last_seq_dup = seq
else:
last_seq_main = seq # 推进主轨参考序号
# --- 解码 & 处理:主音轨 ---
payload_main = main_buf.getvalue()
if payload_main:
pcm_main = decode_mulaw(payload_main)
pcm_main = apply_gain(pcm_main)
pcm_main = remove_silence(pcm_main, sr=SAMPLE_RATE)
else:
pcm_main = np.array([], dtype=np.int16)
wav_main = os.path.join(OUT_DIR, f"rtp_{srcp}_{dstp}_{ssrc}.wav")
save_wav(wav_main, pcm_main, SAMPLE_RATE)
out_files_main.append(wav_main)
per_stream_main.append(((srcp, dstp, ssrc), pcm_main, wav_main))
print(f" [+] 主轨导出:{wav_main}({len(pcm_main)/SAMPLE_RATE:.2f}s)")
# --- 解码 & 处理:重复音轨 ---
payload_dup = dup_buf.getvalue()
if payload_dup:
pcm_dup = decode_mulaw(payload_dup)
pcm_dup = apply_gain(pcm_dup)
pcm_dup = remove_silence(pcm_dup, sr=SAMPLE_RATE)
else:
pcm_dup = np.array([], dtype=np.int16)
wav_dup = os.path.join(DUP_DIR, f"rtp_dup_{srcp}_{dstp}_{ssrc}.wav")
save_wav(wav_dup, pcm_dup, SAMPLE_RATE)
out_files_dup.append(wav_dup)
per_stream_dup.append(((srcp, dstp, ssrc), pcm_dup, wav_dup))
print(f" [=] 重复轨导出:{wav_dup}({len(pcm_dup)/SAMPLE_RATE:.2f}s)")
print(f"\n完成:主轨 {len(out_files_main)} 条,重复轨 {len(out_files_dup)} 条。")
# ======== 合成总音频(主轨) ========
if per_stream_main:
per_stream_main.sort(key=lambda item: (item[0][0], item[0][1], item[0][2]))
gap = np.zeros(int(SAMPLE_RATE * GAP_SECONDS), dtype=np.int16)
parts, names = [], []
for (srcp, dstp, ssrc), pcm, path in per_stream_main:
if pcm.size == 0: continue
parts.append(pcm); names.append(os.path.basename(path)); parts.append(gap)
if parts and parts[-1].size == gap.size:
parts = parts[:-1]
combined = np.concatenate(parts) if parts else np.array([], dtype=np.int16)
comb_path = os.path.join(OUT_DIR, COMBINED_MAIN)
save_wav(comb_path, combined, SAMPLE_RATE)
print(f"[主轨合成] {comb_path} ({len(combined)/SAMPLE_RATE:.2f}s)")
if names:
print(" 顺序:"); [print(f" - {n}") for n in names]
else:
print("[主轨合成] 无可用音频,跳过。")
# ======== 合成总音频(重复轨) ========
if per_stream_dup:
per_stream_dup.sort(key=lambda item: (item[0][0], item[0][1], item[0][2]))
gap = np.zeros(int(SAMPLE_RATE * GAP_SECONDS), dtype=np.int16)
parts, names = [], []
for (srcp, dstp, ssrc), pcm, path in per_stream_dup:
if pcm.size == 0: continue
parts.append(pcm); names.append(os.path.basename(path)); parts.append(gap)
if parts and parts[-1].size == gap.size:
parts = parts[:-1]
combined = np.concatenate(parts) if parts else np.array([], dtype=np.int16)
comb_path = os.path.join(DUP_DIR, COMBINED_DUP)
save_wav(comb_path, combined, SAMPLE_RATE)
print(f"[重复轨合成] {comb_path} ({len(combined)/SAMPLE_RATE:.2f}s)")
if names:
print(" 顺序:"); [print(f" - {n}") for n in names]
else:
print("[重复轨合成] 无可用音频,跳过。")
# ======== 生成排查报告 ========
report = []
report.append(f"# 非RTP/非PCMU 报告")
report.append(f"生成时间: {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
report.append(f"PCAP文件: {os.path.abspath(PCAP_PATH)}")
report.append("")
report.append(f"总帧数: {total_packets}")
report.append(f"IPv4帧数: {total_ipv4}")
report.append(f"UDP报文数: {total_udp}")
report.append(f"RTP报文数: {total_rtp}")
report.append(f"RTP(PT=0, PCMU)报文数: {total_rtp_pcmu}")
report.append("")
if non_ipv4_counts:
report.append("## 非IPv4以太帧 (按EtherType统计)")
for et, cnt in sorted(non_ipv4_counts.items(), key=lambda x: x[0]):
report.append(f"- EtherType={et}: {cnt}")
report.append("")
if non_udp_counts:
report.append("## 非UDP的IPv4报文 (按IP协议号统计)")
for proto, cnt in sorted(non_udp_counts.items(), key=lambda x: int(x[0])):
report.append(f"- IP Proto={proto}: {cnt}")
report.append("")
if udp_non_rtp:
report.append("## UDP但非RTP的流 (按端口对统计)")
for (sp, dp), cnt in sorted(udp_non_rtp.items()):
prefix_hex = (examples_udp_non_rtp.get((sp, dp), "") or "")
report.append(f"- {sp} -> {dp}: {cnt} 报文,样例前缀(<=16B)={prefix_hex}")
report.append("")
if rtp_non_pcmu:
report.append("## RTP但非PCMU的流 (按 src_port, dst_port, PT 统计)")
agg = defaultdict(int)
for (sp, dp, ssrc, pt), cnt in rtp_non_pcmu.items():
agg[(sp, dp, pt)] += cnt
for (sp, dp, pt), total in sorted(agg.items()):
report.append(f"- {sp} -> {dp}, PT={pt}: {total} 报文")
report.append("")
if not (non_ipv4_counts or non_udp_counts or udp_non_rtp or rtp_non_pcmu):
report.append("没有发现异常:全部可疑类别均为空(或样本极少)。")
write_report(report)
print(f"\n[+] 排查报告:{REPORT_PATH}")
if __name__ == "__main__":
main()
提取完后用飞书妙记转录,可以看到里面有两串数字,而且很明显数字都不超过8,一眼八进制(还有114514捏)
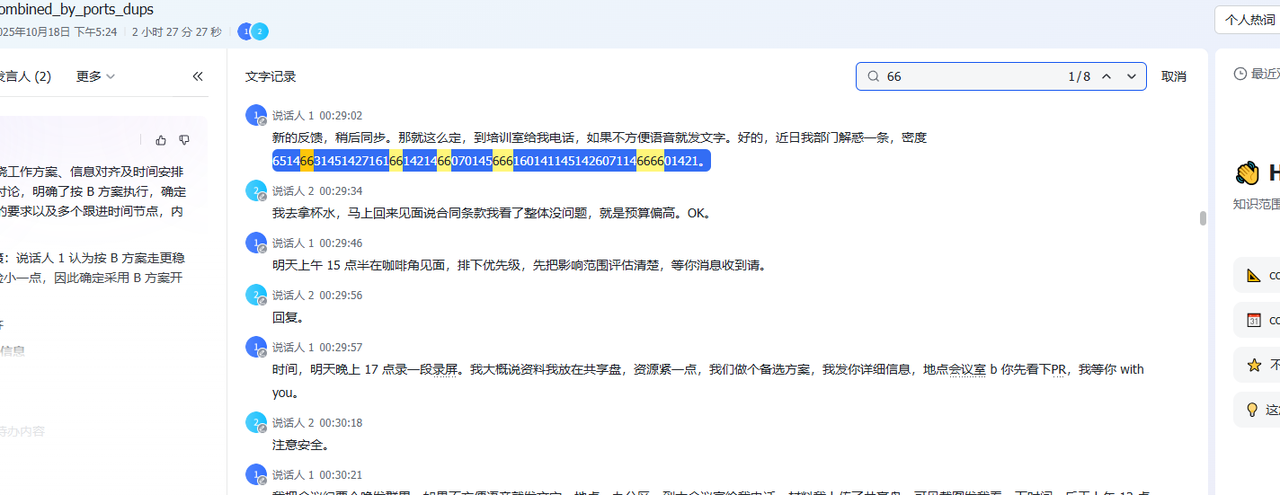
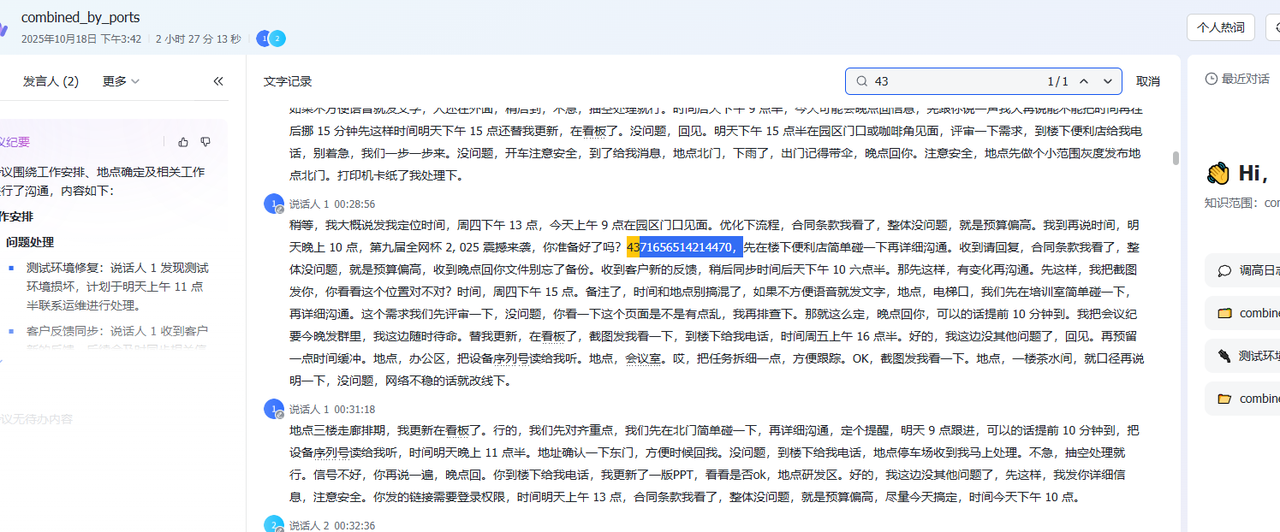
用厨子转一下八进制就好了,这里要手动拆,不然他识别不到
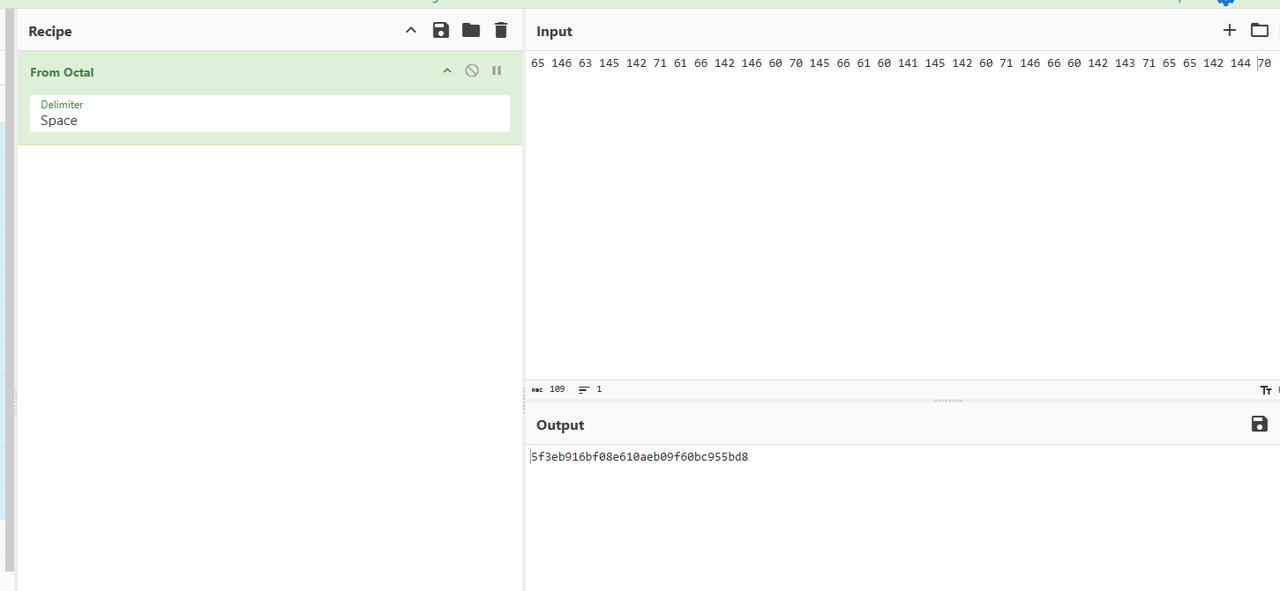
刚刚好拿到32位的hex值,尝试解压加密压缩包发现密码对了

老样子妙记转录音频文字,可以看到有些信息,什么廿四,辰时正过三刻,双里湖西岸南山茶铺,看这个通话看着其实就很间谍那味()
但是这里太谜语了,一直没确定具体的时间,只有地点是确定的

直到后面上了hint,确定要去寻找历史事件(其实有一点猜想,但不确定),音频中提到的双里湖,通过简单社工发现了一个叫双鲤湖的地方,位于福建省金门县,通过大量调查,发现那曾发生过金门战役(没打过以前的强网杯,我还以为张纪星有说法)
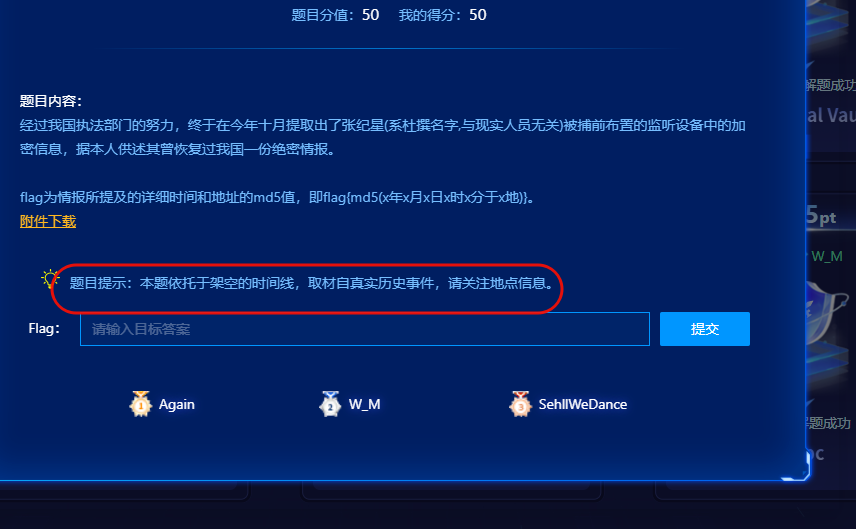

那么时间就确定了是1949年10月24日(一开始以为是25不对,改24对了),然后时分就是8点45分,对应辰时正三刻(这里其实也考虑过是7点45分,但试过也不对),地点就是双鲤湖西岸南山茶铺
md5(1949年10月24日8时45分于双鲤湖西岸南山茶铺)
legacyOLED
知识点省流
OLED数据通信原理 I2C通信协议
WP
(这题凭什么烂,我感觉好难)
附件是一个sr文件,经常打国外赛的都知道,这是什么逻辑分析仪的文件,可以用sigrok的工具打开,下个pulseview打开,发现里面有蜜汁波形
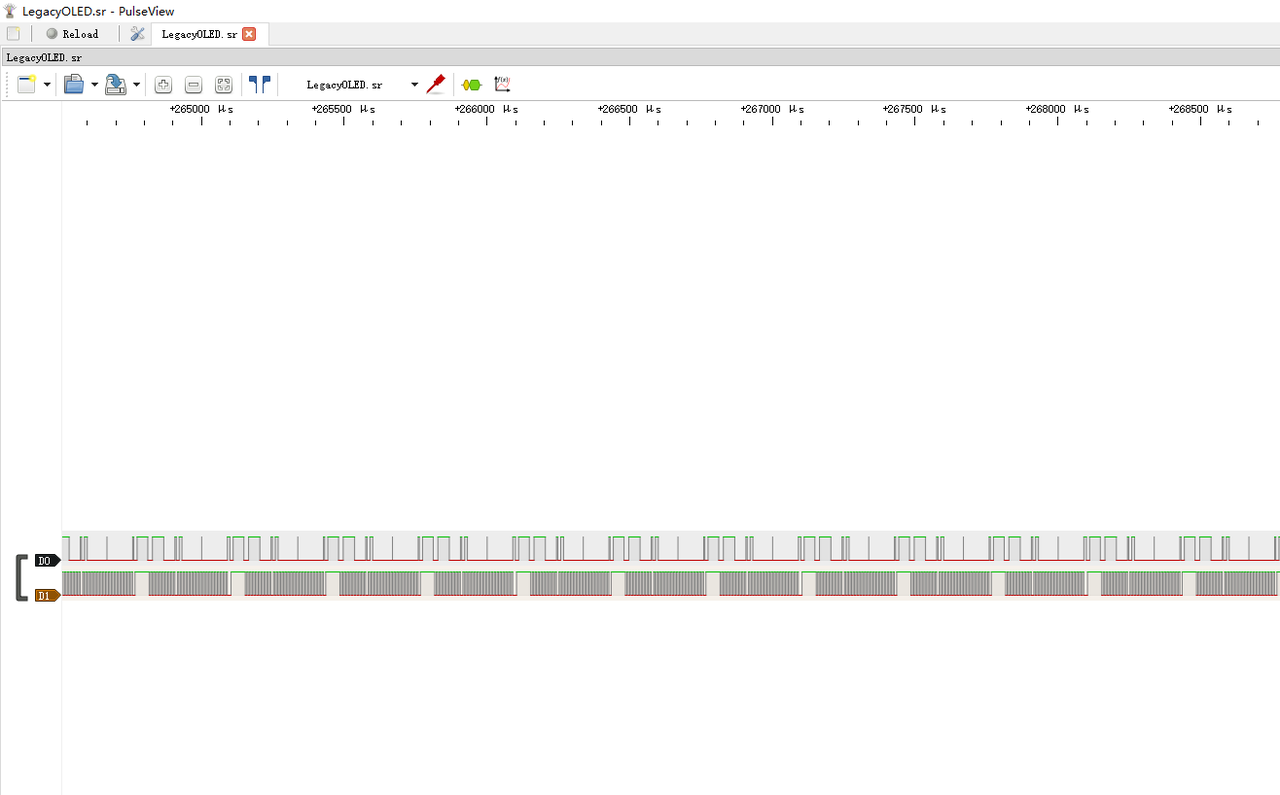
原本的是一些01编码的波形,直到后面队友给我说可能借鉴了这个文章:https://github.com/bobby-tables2/CTF-Archive/tree/87dcb7af1c64705315d6878a7178accf316fe606/CTFSG%202022/SIGINT/Writeup
我简单看了看,发现太像了,遂继续攻破,首先根据题目的OLED和波形的情况,推断这个OLED显示屏的信号数据,一般他的通信协议是I2C,所以可以用I2C对其进行解码,可以发现它传了不少数据的
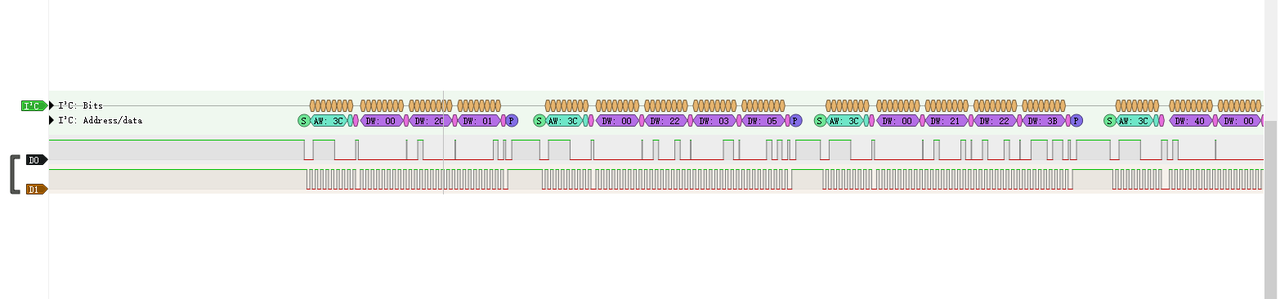
我将数据提取了出来(右键可以导出),然后利用参考的文章的exp跑,发现不行,完全对不上,遂深入研究了OLED和I2C通信的原理
https://blog.csdn.net/weixin_63726869/article/details/133132435
https://zhuanlan.zhihu.com/p/14257150571
通过深入学习上面的两个文章,我确定了,当设备进行地址写入后,传入的第一个数据为控制字节,如果是00则代表传入了命令,40则代表发送给GRAM,然后用于画面打印的(大概就这意思)
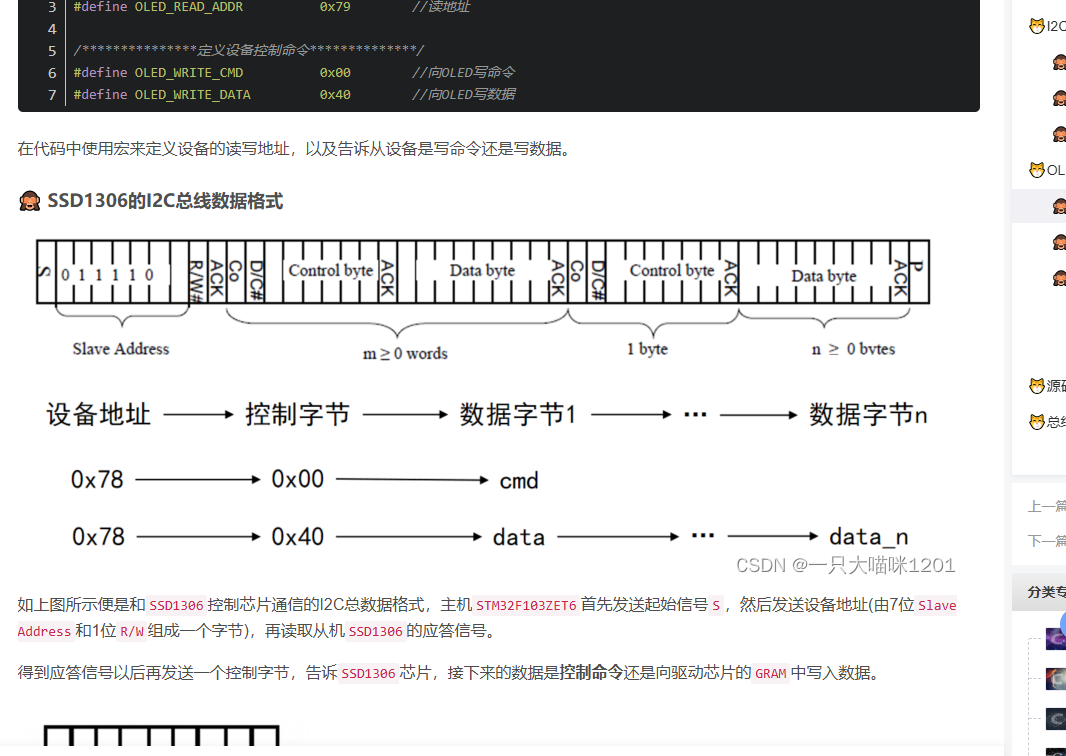
这整段波形中,前面一长串基本是没用的,主要从后一段开始分析,我们可以看到这里断开传入了四次数据,一开始00控制字节,执行了20命令,参数为01,20代表其进行寻址模式调整,参数为01时寻址模式为垂直寻址,00则为水平寻址,后面会出现多次交替,然后是22命令和21命令,分别对应起始/终止页和列,也就是说从哪里开始画起,再往后就是传入40控制字节,开始显示,往后每段都有类似的情况,需要将他们逐一提取然后在参考文章exp的基础上,通过拷打ai问出了一个升级版的脚本

00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[01 21 22 3B 22 03 05]: 00 00 00 00 00 00 C0 00 00 E0 01 00 F8 07 00 FE 1F 00 FF 1F 00 FF 7F 00 FF FF 01 FF FF 07 FF FF 0F FF FF 1F FF FF 7F FF FF FF 3F FE FF 0F FC FF 03 F0 FF E0 E0 FF F8 C3 FF FE 07 FF FF 1F FC FF 3F F8 FF 7F F0 FF 3F F0 FF 1F FC FF 0F FF
[00 21 2E 53 22 06 06]: 00 00 03 07 0F 0F 0F 0F 0F 0F 0F 0F 0F 0F 0F 0F 0F 0F 03 00 00 08 0E 0F 0F 0F 0F 0F 0F 0F 0F 0F 07 03 00 00 00 00
[01 21 00 32 22 00 01]: 00 00 47 00 7E 00 70 00 06 00 06 00 63 00 33 00 00 00 7F 00 6F 00 10 00 33 00 7F 00 3B 00 75 00 00 00 19 00 6F 00 20 00 19 00 39 00 21 00 10 00 00 00 7F 00 5F 00 66 00 22 00 21 00 65 00 3F 00 00 00 4F 00 7F 00 35 00 02 00 5E 00 0B 00 7E 00 00 00 57 00 7F 00 32 00 00 00 12 80 24 E0 47 F0 00 FC 7F FF DF FF
[01 21 30 56 22 02 04]: FF 3F FE FF 0F FC FF 03 F0 FF E0 E0 3F F8 C3 1F FE 07 07 FF 1F C1 FF 3F E0 FF 7F F0 FF 3F FC FF 1F FF FF 0F FF FF 83 FF FF E0 FF 3F F0 FF 1F FC FF 07 FE FF 81 FF 7F E0 FF 1F F8 FF 1F FC FF 07 FF FF C1 FF FF C1 FF FF 83 FF 3F 0F FE 1F 1F FC 0F 3F F0 C3 FF C0 E0 FF 03 F8 FF 07 FE FF 1F FF FF FF FF FF FF FF FF FF FF FE FF FF F8 FF FF F0 FF FF E0 FF 7F
[00 21 30 55 22 00 03]: 00 7F DF 83 C8 D1 A6 BC 80 ED FF B9 60 75 18 3D 00 C7 FF C4 D3 91 84 F6 80 9F EF 8C 92 92 16 1D 00 4B 7F 59 00 19 FC FF FF FF FF FF FF FF 7F 3F 0F 03 C0 E0 F8 FE FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FC F0 E0 80 00 00 00 FF FF FF FF 3F 1F 07 C1 E0 F0 FC FF FF FF FF FF FF FF 7F 1F 1F 07 C1 C1 83 0F 1F 3F FF FF FF FF FF FF FF FE F8 F0 3F 0F 03 E0 F8 FE FF FF FF FF FF FF FF FF 3F 1F 07 81 E0 F8 FC FF FF FF FF FE FC F0 C0 03 07 1F FF FF FF FF FF FF
[01 21 33 59 22 05 07]: FF 0F 00 FF 0F 00 FF 0F 00 FC 0F 00 F8 0F 00 F0 0F 00 F0 0F 00 FC 0F 00 FF 0F 00 FF 0F 00 FF 0F 00 FF 0F 00 FF 0F 00 FF 03 00 FF 00 00 7F 00 00 3F 08 00 0F 0E 00 87 0F 00 C3 0F 00 F0 0F 00 F8 0F 00 FC 0F 00 FF 0F 00 FF 0F 00 FF 0F 00 FF 0F 00 FF 07 00 FF 03 00 FF 00 00 3F 00 00 1F 00 00 0F 00 00 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[00 21 4F 7F 22 00 04]: 1D 00 4B 7F 59 00 19 4A 5E 00 6B 5F 22 71 50 0A 71 00 7B 6F 18 29 23 39 7B 04 6B 77 78 05 33 49 30 04 5F 6B 45 02 58 01 0B 04 36 7B 08 14 18 66 00 FC F0 E0 80 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF FF FE F8 F0 E0 80 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 1F FF FF FF FF FF FF FF FF FE FC F0 60 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF FF FF FF FF 7F 1F 0F 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[00 21 24 35 22 00 02]: 02 5E 0B 7E 00 57 7F 32 00 12 24 47 00 7F DF 83 C8 D1 00 00 00 00 00 00 00 00 00 80 E0 F0 FC FF FF FF FF FF 00 00 00 00 80 E0 E0 F8 FE FF FF FF FF FF FF FF 3F 1F
[01 21 00 7F 22 00 00]: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
import binascii
import re
# OLED显示参数
WIDTH = 128 # 列数
PAGES = 8 # 页数(每页8个像素高)
HEIGHT = PAGES * 8 # 总高度64像素
# 创建二维像素数组
pixels = [['_' for _ in range(WIDTH)] for _ in range(HEIGHT)]
def draw_page_addressing_mode(hex_data):
"""页寻址模式:解析包含10/00指令的数据流"""
global pixels
current_page = 0
current_col = 0
col_start = 0
col_end = 127
i = 0
total_bytes = 0
data_count = 0
while i < len(hex_data):
byte_val = int(hex_data[i], 16)
# 检查是否是列地址低位设置指令 (00H~0FH)
if 0x00 <= byte_val <= 0x0F:
col_low = byte_val & 0x0F
current_col = (current_col & 0xF0) | col_low
print(f" 设置列地址低位: {col_low:X}H, 当前列={current_col}")
i += 1
continue
# 检查是否是列地址高位设置指令 (10H~1FH)
if 0x10 <= byte_val <= 0x1F:
col_high = (byte_val & 0x0F) << 4
current_col = (current_col & 0x0F) | col_high
print(f" 设置列地址高位: {(byte_val & 0x0F):X}H, 当前列={current_col}")
i += 1
continue
# 检查是否是页地址设置指令 (B0H~B7H)
if 0xB0 <= byte_val <= 0xB7:
current_page = byte_val & 0x07
print(f" 设置页地址: {current_page}")
i += 1
continue
# 否则是数据字节
byte_str = f'{byte_val:0>8b}'
# 绘制该字节(一列中一页的8个像素)
if current_col < WIDTH: # 只在有效范围内绘制
for bit in range(8):
row = current_page * 8 + bit
if row < HEIGHT:
if byte_str[7 - bit] == '1':
pixels[row][current_col] = '#'
# 列地址自动递增,限制在0-127范围内
current_col += 1
if current_col > 127: # 超过127就回到起始列
current_col = col_start
# 注意:页地址不会自动改变
data_count += 1
i += 1
return data_count
def draw_horizontal_mode(hex_data, start_col, end_col, start_page, end_page):
"""水平地址模式:先写完一行的所有列,再到下一行"""
global pixels
bin_data = []
for ele in hex_data:
bin_data.append(f'{int(ele, 16):0>8b}')
current_col = start_col
current_page = start_page
for byte_str in bin_data:
if current_page > end_page:
break
for bit in range(8):
row = current_page * 8 + bit
if row < HEIGHT and current_col < WIDTH:
if byte_str[7 - bit] == '1':
pixels[row][current_col] = '#'
current_col += 1
if current_col > end_col:
current_col = start_col
current_page += 1
if current_page > end_page:
break
return len(bin_data)
def draw_vertical_mode(hex_data, start_col, end_col, start_page, end_page):
"""垂直地址模式:先写完一列的所有页,再到下一列"""
global pixels
bin_data = []
for ele in hex_data:
bin_data.append(f'{int(ele, 16):0>8b}')
current_col = start_col
current_page = start_page
for byte_str in bin_data:
if current_col > end_col:
break
for bit in range(8):
row = current_page * 8 + bit
if row < HEIGHT and current_col < WIDTH:
if byte_str[7 - bit] == '1':
pixels[row][current_col] = '#'
current_page += 1
if current_page > end_page:
current_page = start_page
current_col += 1
if current_col > end_col:
break
return len(bin_data)
# 读取文件
with open("pixel.txt", "r") as f:
lines = f.readlines()
# 第一行:页寻址模式(默认)
print("=" * 60)
print("第一阶段:页寻址模式")
print("=" * 60)
if lines:
first_line = lines[0].strip()
if first_line:
hex_data = first_line.split()
print(f"处理页寻址模式数据,共 {len(hex_data)} 字节")
bytes_used = draw_page_addressing_mode(hex_data)
print(f"绘制了 {bytes_used} 个数据字节\n")
# 后续行:动态模式(带指令)
print("=" * 60)
print("第二阶段:动态地址模式")
print("=" * 60)
line_num = 1
for line in lines[1:]:
line_num += 1
line = line.strip()
if not line:
continue
# 解析格式: [yy 21 xx xx 22 xx xx]:
match = re.match(
r'\[([0-9A-Fa-f]{2})\s+21\s+([0-9A-Fa-f]{2})\s+([0-9A-Fa-f]{2})\s+22\s+([0-9A-Fa-f]{2})\s+([0-9A-Fa-f]{2})\][::]\s*(.*)',
line)
if not match:
print(f"第 {line_num} 行格式不正确,跳过: {line[:50]}...")
continue
mode_byte = match.group(1)
start_col = int(match.group(2), 16)
end_col = int(match.group(3), 16)
start_page = int(match.group(4), 16)
end_page = int(match.group(5), 16)
hex_data_str = match.group(6).strip()
hex_data = hex_data_str.split()
if mode_byte == "00":
mode = "水平"
bytes_used = draw_horizontal_mode(hex_data, start_col, end_col, start_page, end_page)
elif mode_byte == "01":
mode = "垂直"
bytes_used = draw_vertical_mode(hex_data, start_col, end_col, start_page, end_page)
else:
print(f"第 {line_num} 行未知模式: {mode_byte},跳过")
continue
print(
f"第 {line_num} 行 | {mode}模式 | 列[{start_col}:{end_col}] 页[{start_page}:{end_page}] | 数据: {len(hex_data)} 字节")
# 输出图像
print("\n" + "=" * 60)
print("最终OLED图像输出:")
print("=" * 60 + "\n")
print(f"图像尺寸: {WIDTH}列 x {HEIGHT}行")
print(f"实际像素数组: {len(pixels)}行 x {len(pixels[0])}列\n")
for row in pixels:
for col_idx in range(min(WIDTH, len(row))): # 只输出WIDTH列
print(row[col_idx], end=' ')
print()
# 保存为文本文件
with open("oled_output.txt", "w") as f:
for row in pixels:
for col_idx in range(min(WIDTH, len(row))): # 只输出WIDTH列
f.write(row[col_idx] + ' ')
f.write('\n')
print("\n图像已保存到 oled_output.txt")
最后终于成功了,画出了一个强网杯的logo,上面乱乱的看不出是什么,以为是我脚本错了,后面发现是将_#转01然后解二进制就可以了

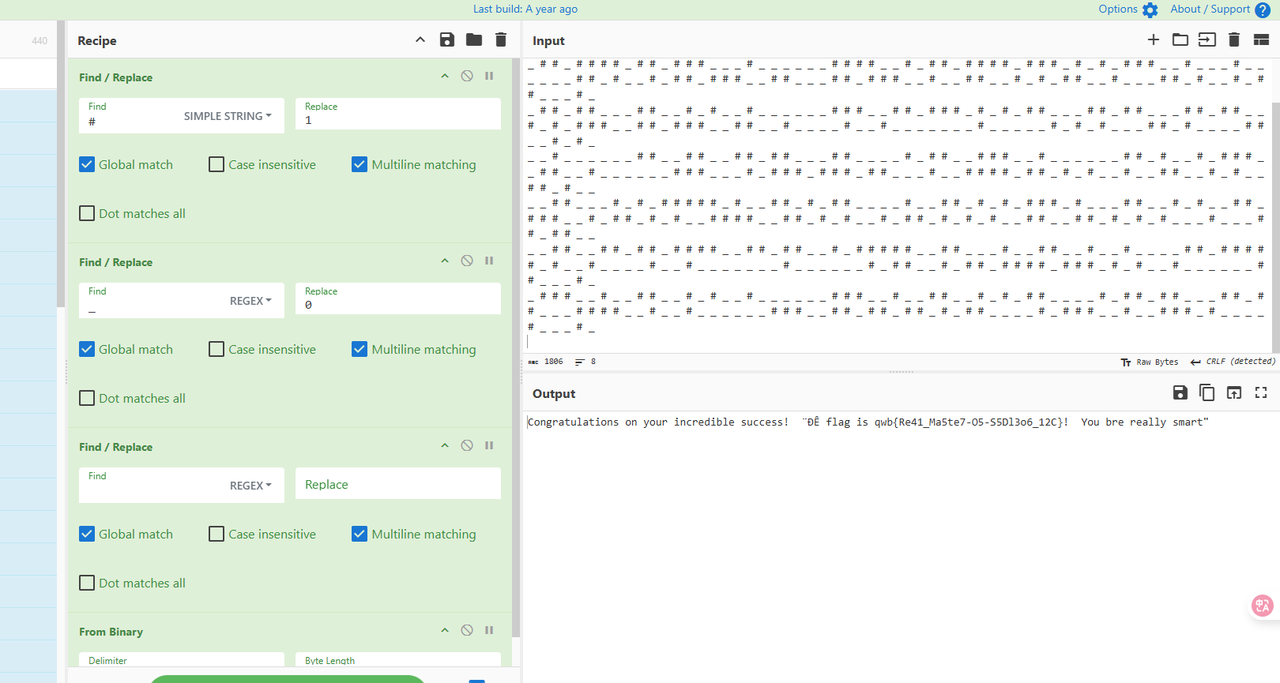
Secured Personal Vault(唯一血)
知识点省流
内存取证但又是非预期(进程内存转储查看窗口画面)
WP
坚不可摧这块,而且又非了(
依旧内存取证,但是把早上的非预期修了,爆搜搜不到,分析一下发现桌面有个apersonalvault.exe(早上的取证做过也能知道)
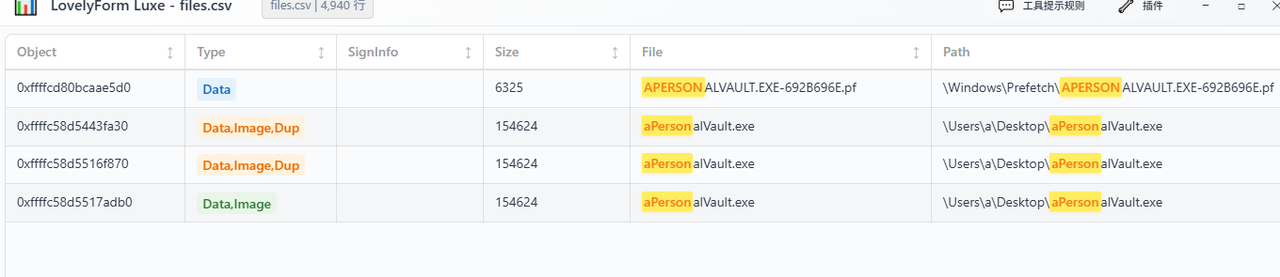
提出来丢给逆向手逆向了,他们说要找密文,exe里自带了解密什么的,但是生成的mailslot文件提取不出来,拿不到,也没什么多的头绪了,没招了,也没人做出来,感觉到此为止了
……
但是真没招吗
并非
我们miscer有我们miscer自己的做法
让我们将时间倒退到10月12日,在今年的羊城杯赛事中,我负责了一道内存取证的题目(你也是旮旯给木大师?),其中的第四问,我的预期解是需要通过提取dwm.exe的进程内存转储来实现对qq程序窗口的取证(不提dwm也行,提qq进程也可以的应该)
于是乎,19号凌晨,当我学了一晚上OLED原理并把OLED做出来后,估摸是一晚上没怎么睡脑子不太正常抽风了,寻思看看他的窗口管理器内存转储,也就是dwm.exe的内存转储,遂提取了一波,用马处的lovelymem luxe提取内存转储,然后用lovelypixelweaver进行爆看
由于不确定分辨率,所以我手动爆了一下,最后发现是1279这个宽度可以正常看到窗口信息,然后我就滑了滑偏移,没想到啊,真的有出题人在加密flag时的窗口画面,但是有点花,只能明显的看到flag头一部分,后面的部分都混在一起了,不过不影响我通过强大的视力再加上一点点小小的英语语法功底和毅力,将他盯出来了(需要不断切换一下偏移量,图像格式和位深度)
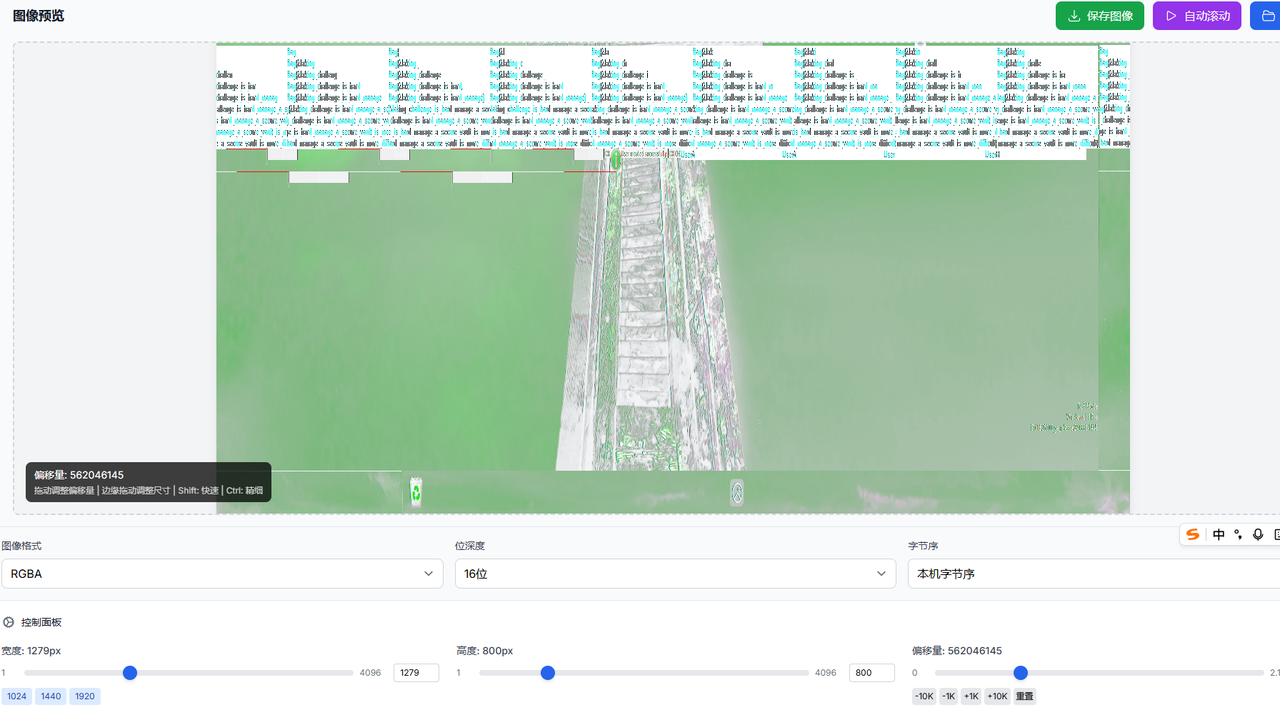

flag最后盯帧出来为
flag{Making_challenge_is_hard_manage_a_secure_vault_is_more_difficult}
至此该系列顺利完成,最终以双非(两次非预期)的形式结束了这个内存取证
顺带一提,直至该WP撰写完成(指的是我博客这版,这版跟比赛交上去的不一样),某Re手群内已经出现了该题的正确预期解法,十分佩服Re大手子的实力,这边贴一下预期解的帖子给看到这的师傅去学习一下( https://blog.moshui.eu.org/2025/10/22/qwb-SecuredPersonalVault-wp/ )
胡言乱语
(这只是一个什么都不懂的萌新的胡言乱语罢了)
诚然我十分理解现在misc中夹杂着各个方向(甚至超出五大基础方向)的内容,作为一名misc手也不应该围绕着自己那一亩三分地,永远困在经典misc(编码隐写等)的舒适圈中。但就现今而言,misc掺杂其他方向的内容变得越来越硬核了,以Secured Personal Vault为例,预期解甚至是一位Re师傅解出的,这是不是意味着misc手需要完成这道题目还得具备十分硬核的逆向能力;但反过来想既然能具备硬核的逆向能力,我为什么不去做re手呢……
有的时候我们会调侃,misc手的终点其实是全栈手,现在看来兴许并非是调侃,当有一天misc的题目都结合了其他方向的硬核知识后,我们不就真的全栈了,亦或者misc手就不复存在了(因为交给其他方向的师傅来做就好了,人人都可以是misc手)
misc手的出路在哪,我也很想知道……但也许,我们都需要重新审视一下misc这个方向,灵活变通,适应环境是我们misc手的特点,正因如此,拥抱变化,突破边界才应该是我们的方向。希望每一位misc手都能找到属于自己的突破口,共勉。

