.png)
H&NCTF2025 - Misc、Forensic、Osint - WriteUp
[队伍名] - 友情&羁绊
[ranking] - 3
碎碎念
感觉最近有点倦怠了,博客更新的也少了)以后会考虑搞点有深度的更技术的玩意,一位的写wp也不是办法
这次也是很开心能参加H&NCTF2025,题目质量我觉得蛮不错的,挺有意思,虽然有几题我实在是没研究出来,前一天出去了几乎没怎么打,后面是通宵补上的(身体要不行了) 也是感谢队友带飞最终取得了第三的好成绩qwq
Misc:
芙宁娜的图片
给了文档和图片,图片lsb藏了一个key,随波逐流直接梭出来

文档内容brainfuck得到一个加密的flag

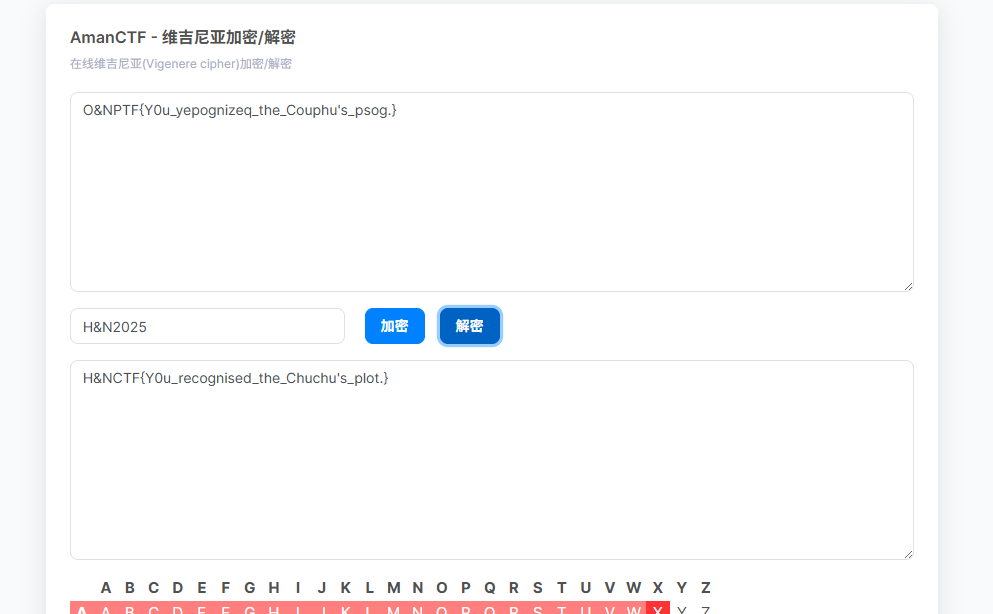
拿bugku的维吉尼亚解密即可
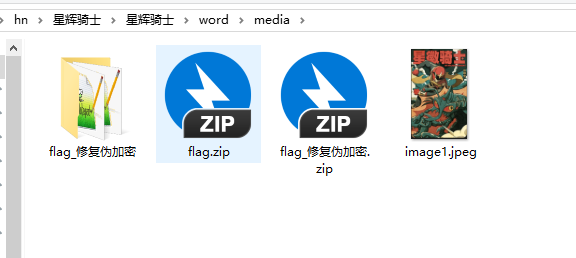
星辉骑士
得到一个docx文档,修改zip后缀,在media里找到一个压缩包,然后随波梭哈修改伪加密
解压得到一堆文档,打开可以看到是垃圾邮件隐写
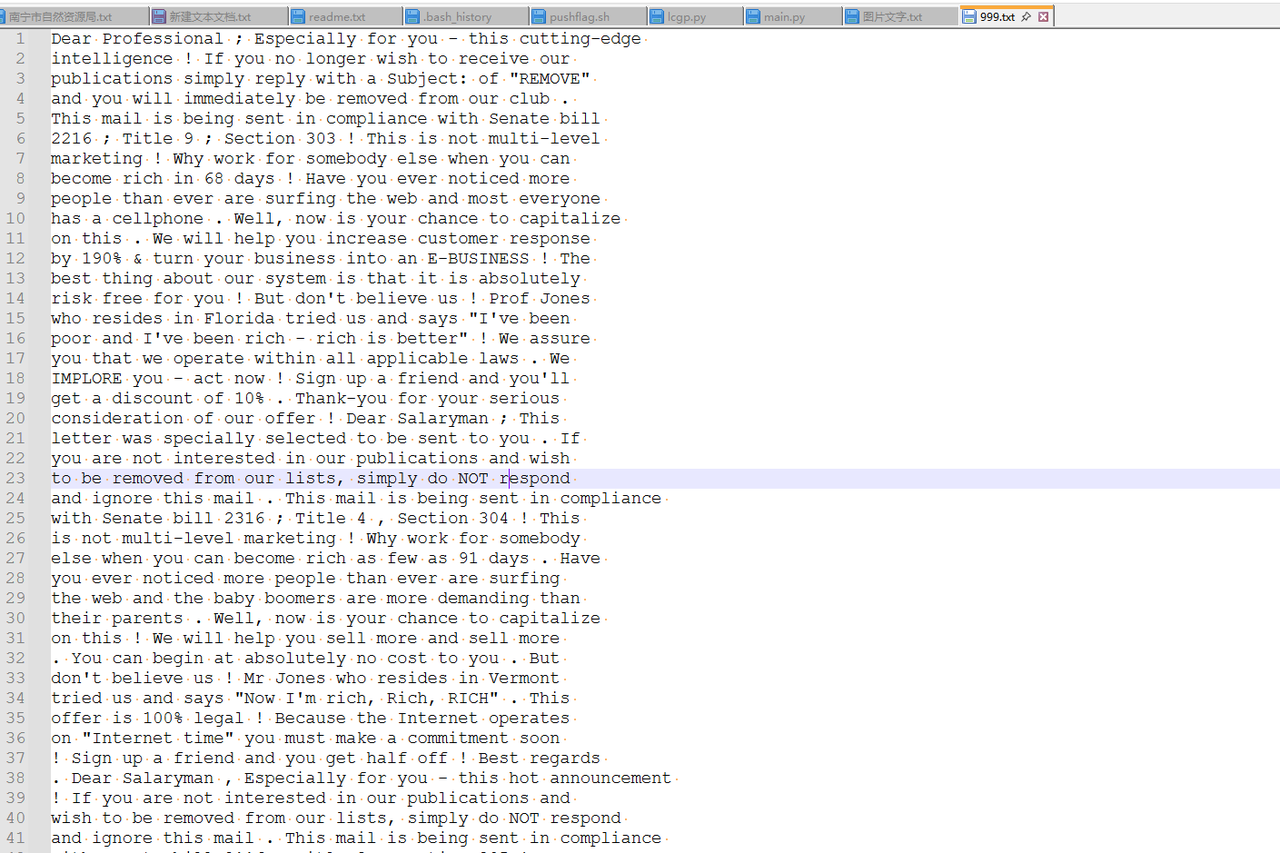
一个个解一下隐写即可https://spammimic.com/decode.cgi

乱成一锅粥了
wireshark打开分析,导出http对象可以发现有好几个压缩包,全部拉出来后,解压发现每个压缩包里都有50个txt文档,而且命名都一样
观察发现名字都是32位的小写字母和数字,猜测是md5值,所以去cmd5解密一下发现是50以内的shu猜到是逆出序号后按照序号拼接,写脚本处理即可:
import os
import re
import hashlib
# 1. 构建数字 1–50 到对应 md5 值的映射
# 数字 <10 时使用两位格式 01-09,其余正常
def build_md5_map():
md5_map = {}
for i in range(1, 51):
# 小于10时补0
s = f"{i:02d}" if i < 10 else str(i)
h = hashlib.md5(s.encode('utf-8')).hexdigest()
md5_map[h] = i
return md5_map
# 2. 主函数:遍历、筛选并重命名
def rename_files_by_md5(input_dir, output_dir):
"""
遍历 input_dir 下的所有.txt文件,
匹配文件名是否为32位小写十六进制MD5,
并根据映射生成 outputs 目录下对应序号的文件
"""
os.makedirs(output_dir, exist_ok=True)
md5_map = build_md5_map()
pattern = re.compile(r"^[0-9a-f]{32}$")
for fname in os.listdir(input_dir):
if not fname.lower().endswith('.txt'):
continue
name = fname[:-4].strip().lower()
if not pattern.fullmatch(name):
continue
num = md5_map.get(name)
if num is None:
print(f"Warning: 未找到对应序号的MD5:{name}.txt")
continue
src = os.path.join(input_dir, fname)
dst = os.path.join(output_dir, f"{num}.txt")
with open(src, 'r', encoding='utf-8') as f_src:
content = f_src.read()
with open(dst, 'w', encoding='utf-8') as f_dst:
f_dst.write(content)
print(f"生成: {num}.txt")
if __name__ == '__main__':
INPUT_DIR = 'txt/End/End' # 包含 MD5 文件的目录
OUTPUT_DIR = 'outputs'
rename_files_by_md5(INPUT_DIR, OUTPUT_DIR)
import os
def merge_txt_files(input_dir, output_file='merged.txt'):
with open(output_file, 'w', encoding='utf-8') as outfile:
for i in range(1, 51):
filename = os.path.join(input_dir, f'{i}.txt')
try:
with open(filename, 'r', encoding='utf-8') as infile:
content = infile.read()
outfile.write(content)
# outfile.write('\n') # 可选:每个文件之间加一个换行
except FileNotFoundError:
print(f'Warning: {filename} not found, skipping.')
if __name__ == '__main__':
# 示例路径:请替换为你的目录路径
input_directory = 'outputs'
merge_txt_files(input_directory, output_file='merged.txt')
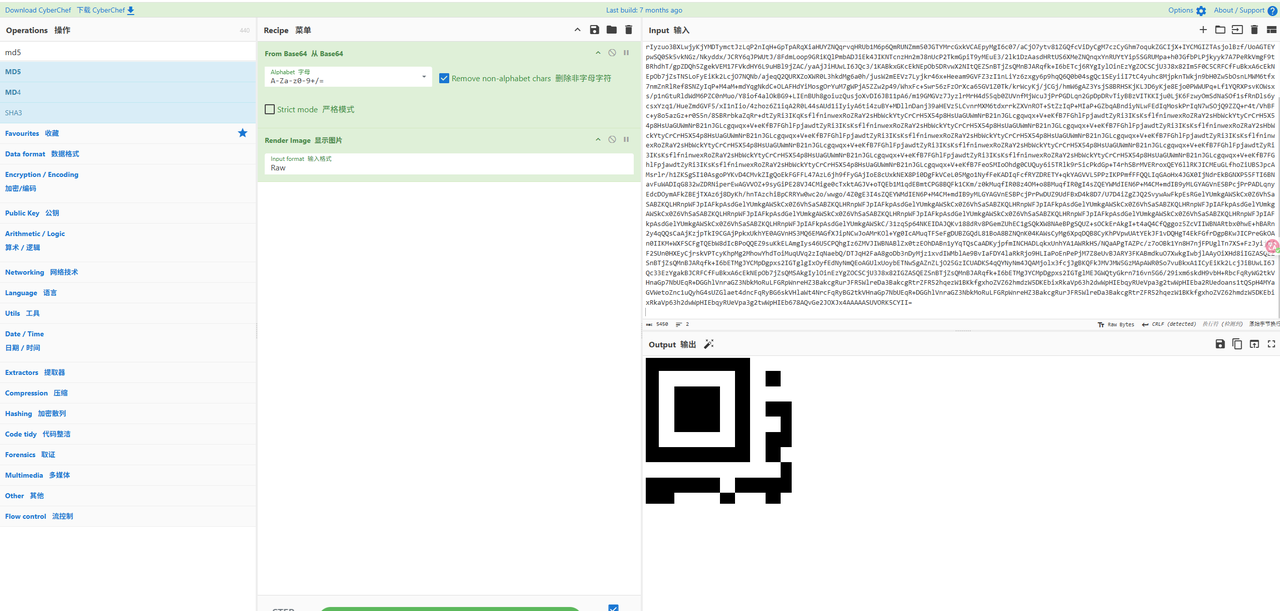
拼完一个厨子一下得到二维码一部分,拼完剩下的即可

Forensics:
ez_game
给了一个vhd硬盘镜像,直接拿ufs分析一下,发现两个部分都放了内容,全部提取出来

根据txt的内容确定是要用jpg作为密钥挂载,挂载后得到一个虚拟机文件

老样子ufs分析,在root目录找到bash_history,得到两个关键信息,分别为两个key
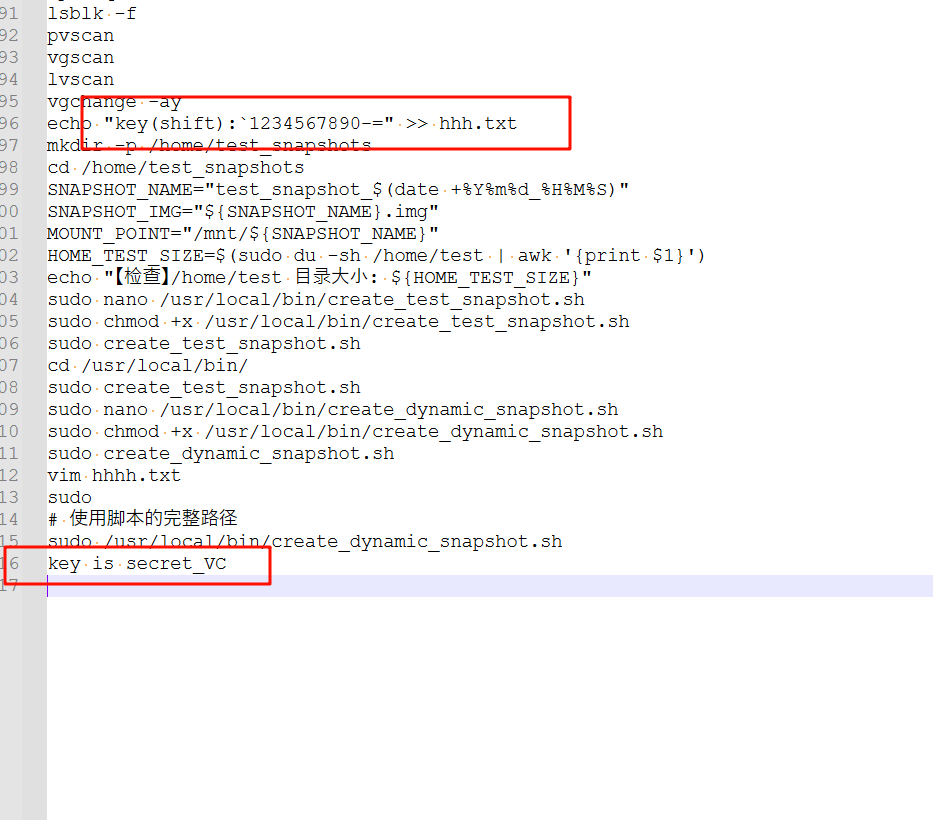
一开始暂时不确定上面那个是什么,用下面那个重新挂载提取的vera容器,读取到隐藏空间发现藏了个加密压缩包
而密码就是上面提到的内容,他的意思就是按住shift后从`按到+即为密码(也就是~!@#$%^&*()_+)
解压后得到一个drawio文件,问问gpt是什么然后得到一个在线网站丢进去即可得到flag

OSINT:
Chasing Freedom 1
H&NCTF{0503-丁鼻垄}
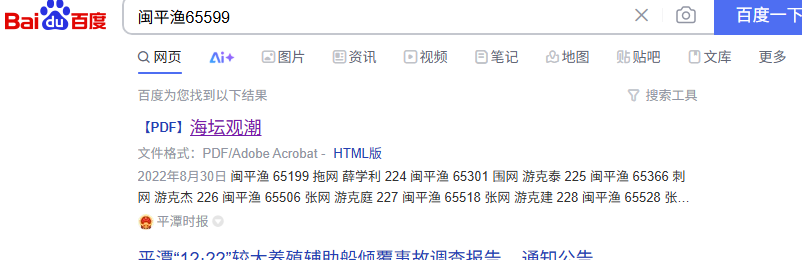
时间都在图片的属性里,图片有一个船,可以看到船号是闽平渔65599

百度一搜,第一个就是一个pdf文件
打开搜索65599确定这个船的所有人地址

然后搜一下就发现旁边有个叫丁鼻垄的地方,交一下发现对了

Chasing Freedom 2
H&NCTF{0504-东庠岛灯塔}
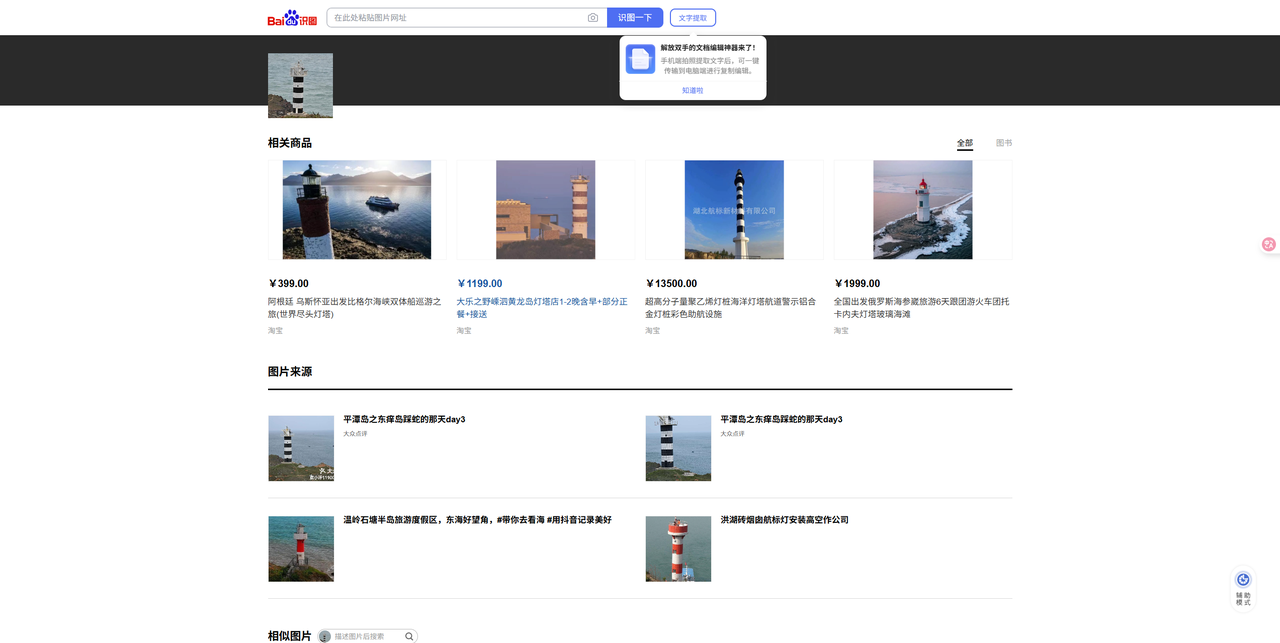
时间都在图片的属性里,将图片的灯塔截取出来百度搜图就能找到事东庠岛的灯塔了
Chasing Freedom 3
H&NCTF{0504-流水码头-岚庠渡3号}
时间都在图片的属性里,图片下面可以看到是岚庠渡

微信一搜,码头和船号都有了,遍历一下就好了



