
CTF-misc专项学习笔记01——入门
一些废话
根据实验室的培训方针,最近开始针对学习MISC方向的内容,故而得到了这篇学习笔记
暂时没想好是分开记录还是统一写在这里,暂时先分开吧
因为要交任务,所以有些内容还没写全,后续会做补充
笔记参考
https://goodlunatic.github.io/posts/1ad9200/
https://ctf-wiki.org/misc/introduction/
简要介绍
Misc 是英文 Miscellaneous 的前四个字母,杂项、混合体、大杂烩的意思
主要包含以下几个大方向:
-
Recon(信息搜集)
主要介绍一些获取信息的渠道和一些利用百度、谷歌等搜索引擎的技巧
-
Encode(编码转换)
主要介绍在 CTF 比赛中一些常见的编码形式以及转换的技巧和常见方式
-
Forensic && Stego(数字取证 && 隐写分析)
隐写取证是 Misc 中最为重要的一块,包括文件分析、隐写、内存镜像分析和流量抓包分析等等,涉及巧妙的编码、隐藏数据、层层嵌套的文件中的文件,灵活利用搜索引擎获取所需要的信息等等。
CTF 中 Misc 与现实中的取证不同,现实中的取证很少会涉及巧妙的编码加密,数据隐藏,被分散嵌套在各处的文件字符串,或是其他脑洞类的 Challenge。很多时候是去精心恢复一个残损的文件,挖掘损坏硬盘中的蛛丝马迹, 或者从内存镜像中抽取有用的信息。
现实的取证需要从业者能够找出间接的恶意行为证据:攻击者攻击系统的痕迹,或是内部威胁行为的痕迹。实际工作中计算机取证大部分是从日志、内存、文件系统中找出犯罪线索,并找出与文件或文件系统中数据的关系。而流量取证比起内容数据的分析,更注重元数据的分析,也就是当前不同端点间常用 TLS 加密的网络会话。
Misc 是切入 CTF 竞赛领域、培养兴趣的最佳入口。Misc 考察基本知识,对安全技能的各个层面都有不同程度的涉及,可以在很大程度上启发思维。
下图为misc题型及对应工具的导图
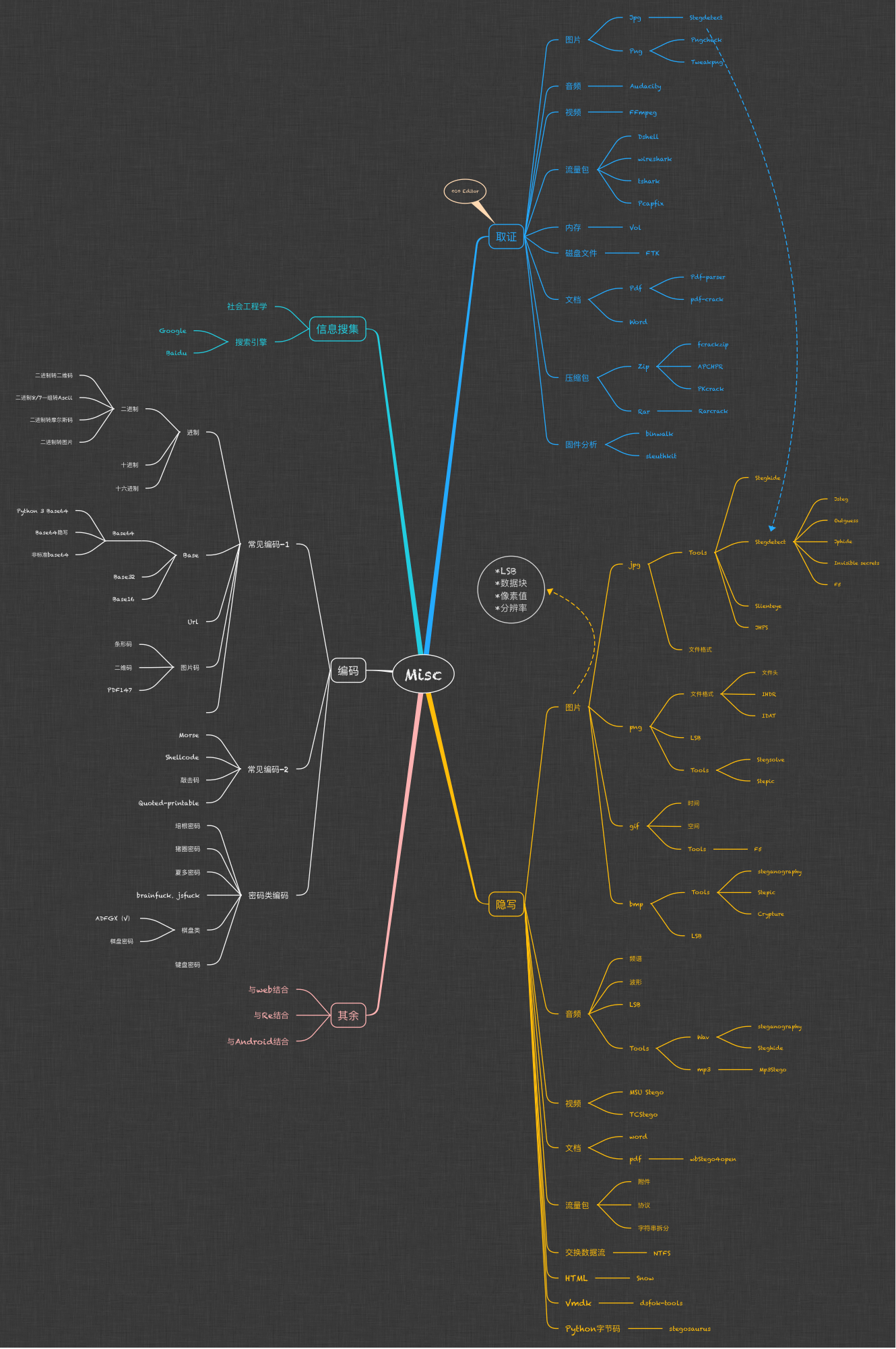
信息搜集
简介
信息搜集,也称为开源情报获取——Open source intelligence(OSINT),这是一种情报搜集手段,从各种公开的信息资源中寻找和获取有价值的情报。
这类题目也就是我们常说的社工题(社会工程学),通常以各类标志性建筑,街景,行程信息等内容的 图片 作为题目,选手需要从有限信息中不断检索修补信息差,寻找细节突破点,依次来获得题目要求的信息 —— 拍摄地点,拍摄人的一些身份信息等。
OSINT 题目是比较吃经验和技巧的(个人觉得非常的好玩)
题型
图片定位
对于仅给定图片的 OSINT 题目,通常从图片本身和图片内容入手。
(下图为学校新手赛中出的一道社工题,要求找出图片左边的大厦名)

文件信息
一些图片的 EXIF 信息中可能含有拍摄的经纬度,角度,设备型号等信息,通过图片 经纬度 + 图片内容 进行误差修正的 OSINT 题目也算是简单题目中的常客。
街景
街景的维度很广,以下是几个常见的检索方向:
- 建筑风格
- 从是否有地标性或者其他标志性建筑
- 显眼的店铺名称
- 各种路牌 指示牌
- 围栏特征
- 车牌
- 行人服饰特点
交通要地
如 火车站,地铁站,机场,码头等。
- 布局
- 各类提示性文字 指示牌
- 交题工具是否出镜 —— 外形 具体型号
行程信息
如 各类车票 / 机票 ,已对部分要素打码,但依旧能获取到其他如 时间等有效要素的图片。
相关工具
图片搜索
| 网站名称与网址 | 描述 |
|---|---|
| 谷歌识图 | 优秀的图片搜索引擎,以搜索效果著称。手机用户可点击浏览器菜单→开启“浏览电脑版网页”以访问上传图片功能。 |
| 百度识图 | 适合中文网站图片资源搜索的工具。 |
| 搜狗识图 | 提供人性化的图片识别功能,包括「通用识图」「猫狗识别」「明星识别」「找高清大图」等选项,根据需求选择提高识别效率。 |
| Yandex.Images | 俄罗斯最受欢迎的搜索引擎,支持英文搜索。在其他搜索引擎无法找到结果时,不妨尝试使用 Yandex 以获取更好的搜索效果。 |
| TinEye | 老牌图片逆向搜索引擎,资源丰富。安装浏览器插件后可通过右键菜单直接使用。 |
| 必应可视化搜索 | 由微软必应推出的视觉搜索引擎,支持特色搜索如植物、商品、家具、宠物、文字、人物、建筑等。 |
| What Anime Is This? | 动漫视频截图识别工具,专为动漫迷设计。可通过视频截图找到动画图片的来源和片段位置。 |
| SauceNAO Image Search | 知名的图片逆向搜索引擎,对动画、漫画、插画、二次元等领域有出色的识图效果。可获取图片来源和作者主页链接。包含数十亿张图像,尤其在 Pixiv(pixiv.net)的识别效果出色。 |
定位辅助
| 网址 | 描述 |
|---|---|
| Google Geolocation | 谷歌地理定位 |
| 移动 OneNET 平台 | 智能硬件位置定位 |
| OpenGPS | 高精度定位 |
| CellLocation | 经纬度、WiFi mac 地址、BSSID、gps |
| Seeker | 获取高精度地理信息和设备信息的工具 |
| MAC 地址查询工具 | MAC 地址库查询工具 |
| MaxMind GeoIP | geoip2 全球 IPV4 |
| IPIP | IPV4,可查 IP 归属数据中心。 |
| IPPlus360 | IPV4/IPV6 地址库。 |
| OpenCellID | GSM 定位 |
| SunCalc | 通过太阳和投射的阴影进行人员地理位置定位 |
| IP数据云 | 提供一系列数据服务,如IP归属、域名信息等 |
社交媒体
| 网站名称与网址 | 描述 |
|---|---|
| lyzem.com | Telegram 搜索引擎。 |
| Social Mapper | 由 Trustwave 公司 SpiderLabs 开源的社交媒体枚举和关联工具,通过人脸识别关联人物侧写。 |
| Sniff-Paste | 针对 Pastebin 的开源情报收集工具。 |
| Linkedin2Username | 通过 Linkedin 领英获取相关公司员工列表的工具。 |
| Mailget | 通过脉脉用户猜测企业邮箱的工具。 |
| Picdeer | Instagram 内容和用户在线搜索工具。 |
| Ransombile | 用于根据社交媒体密码找回信息的 Ruby 工具。 |
| Reg007 | 查找注册过的网站和应用的工具。 |
| Check Your Weibo | 微博互关检测脚本的工具。 |
交通运输
| 网站名称与网址 | 描述 |
|---|---|
| Flightradar24 | 提供全球实时飞行跟踪信息。 |
| MarineTraffic | 提供全球船舶跟踪情报。 |
相关技巧
基本搜索
-
Google 基本搜索与挖掘技巧
-
保持简单明了的关键词
-
使用最可能出现在要查找的网页上的字词
-
尽量简明扼要地描述要查找的内容
-
选择独特性的描述字词
-
社会公共信息库查询
-
个人信息:人口统计局
-
企业等实体:YellowPage、企业信用信息网
-
网站、域名、IP:whois 等
信息搜索
- 公开渠道
- 目标 Web 网页、地理位置、相关组织
- 组织结构和人员、个人资料、电话、电子邮件
- 网络配置、安全防护机制的策略和技术细节
- 通过搜索引擎查找特定安全漏洞或私密信息的方法
- Google Hacking Database
- 科学上网
地图街景搜索
- 国外:Google Map、Google Earth、Google Street View
- 国内:百度地图、卫星地图、街景
- 从网络世界到物理世界:IP2Location
- whois 数据库
- GeoIP
- IP2Location
- 纯真数据库(QQ IP 查询)
编码分析
OK正式开始这章的内容前,请让我们先了解一下what is 编码——
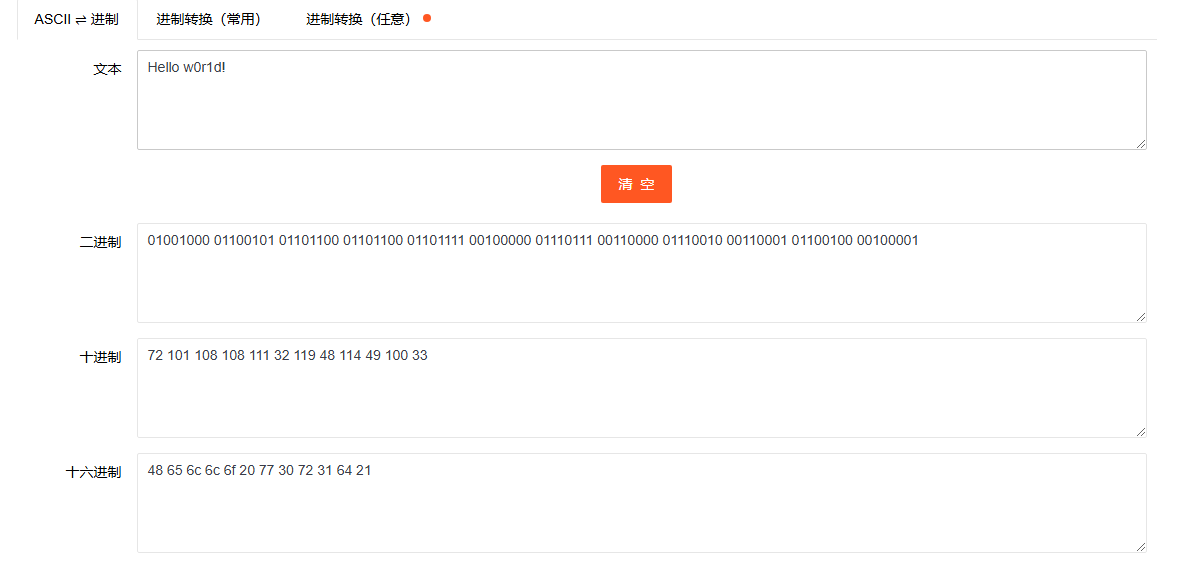
下面的编码展示我们都以**Hello w0r1d!**作为原文本
编码基础
简介
编码不同于密码,他的关键不是隐藏信息,而是处理信息,是信息的另一种表示形式,用于解决一些特殊字符、不可见字符的传输问题。
将原始信息变成编码信息的过程为 「编码 Encoding 」,反之,将编码信息转化回原始信息,转化的过程称之为 「解码 Decoding 」。
编码很少单独作为题目出现在 CTF 中,除开 T0 级别的签到题目,多数情况都贯穿 CTF 的各个方向,包括但不限于 杂项 和 密码学。
常见编码
ASCII编码
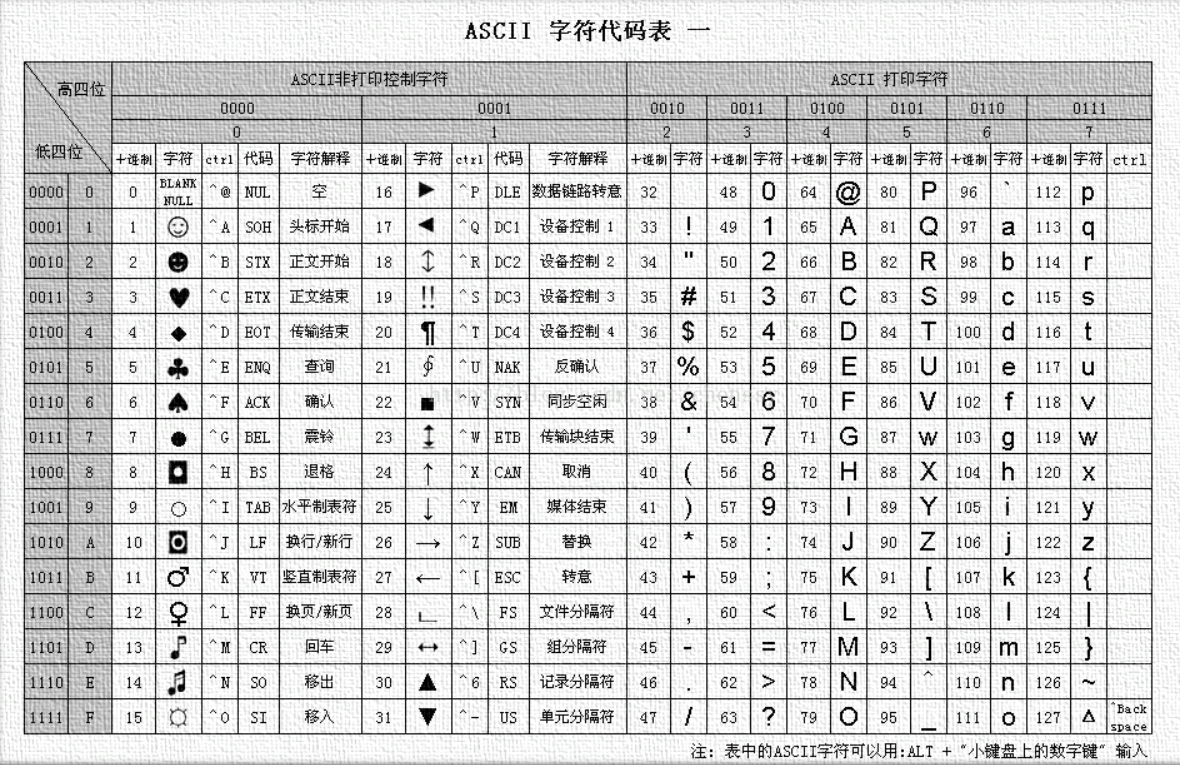
一种使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符的编码方式。
上面的 ASCII 表使用的「十进制 Decimal 」来表示对应的值,这也是我们通常使用的方法
一般使用ASCII编码的时候采用的都是一些可见字符,主要如下:
- 0-9 ——> 48-57
- A-Z ——> 65-90
- a-z ——> 97-122
ASCII编码还可以转换成二进制表示或者十六进制表示
二进制编码:
- 只有0和1
- 不大于8位,一般为7位,因为可见字符到127
十六进制编码:
- A-Z ——> 0x41~0x5A
- a-z ——> 0x61~0x7A
将**Hello w0r1d!**进行ASCII编码后可得到:
Hex
「Hex Hexadecimal 」 意为 "十六进制",虽然十六进制经常用于与编码相关的上下文中,但它并不是一种编码,只是一种数值表示法。只不过在 CTF 中有时会以签到题目出现,比如:
666c61677b5371756467792066657a2c20626c616e6b206a696d7020637277746820766f787d
From Hex to String ,即十六进制转字符串,目前在赛题已经不在常见。
将**Hello w0r1d!**进行Hex编码后可得到:
48656c6c6f20773072316421
Base家族
basexx中的xx表示的是采用多少个字符进行编码,Base 家族的编码方式提供了一种方法,将原始的二进制数据转换成一个更“友好”的、由特定字符集组成的字符串格式,比如 base64、base32、base16 可以分别编码转化 8 位字节为 6 位、5 位、4 位。16,32,64 分别表示用多少个字符来编码。
以 Base64 为例:
其编码过程为:
- 将输入数据分割成长度为 3 的字节组。
- 将这三个字节转换为 4 个 6 位的组。这样做是通过将这三个字节(总共 24 位)重组为 4 个 6 位的数值。
- 使用这 4 个 6 位的数值作为索引,从 BASE64 字符集中选择对应的字符。
- 如果输入数据的字节长度不是 3 的倍数,就在输出的 BASE64 字符串后面加上一个或两个 '=' 字符作为填充。
源文本:Go
G -> 01000111
o -> 01101111
得到8位binary:01000111 01101111
分组为6位binary:010001 110110 1111
补0:010001 110110 111100
对应十进制:17 54 60 (为数组下标)
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
-----------------↑------------------------------------↑-----↑---
010001 -> R
110110 -> 2
111100 -> 8
查表得:R28
补齐得:R28=
解码过程则是编码的逆过程:
- 把 Base64 字符串去掉等号,转为二进制数
- 从左到右,8 个位一组,多余位的扔掉,转为对应的 ASCII 码
密文: R28=
去掉=:R28
对应十进制(ASCII 码): 17 54 60
还原位6位二进制 : 010001 110110 111100
重新分组为8位二进制: 01000111 01101111 00
8位二进制转换为对应ASCII码: G o /(丢弃不完整部分)
得到原文:Go
以下是一些常用的Base编码对应的字符集和对应说明
| 编码 | 字符集 | 备注 |
|---|---|---|
| BASE2 | 01 | 二进制 |
| BASE16 | 0123456789ABCDEF (或0123456789abcdef) | 十六进制 |
| BASE32 | ABCDEFGHIJKLMNOPQRSTUVWXYZ234567 | 最多6个=号 |
| BASE32Hex | 0123456789ABCDEFGHIJKLMNOPQRSTUV | Base32 的变体 |
| BASE58 | 123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz | 注意,这个集合避免了容易混淆的字符,例如数字“0”和大写的字母“O”;主要用于比特币地址 |
| BASE64 | ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ | 最多2个=号 |
| BASE64URL | ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_ | 适用于 URL 和文件名 |
| BASE85 | !\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_abcdefghijklmnopqrstu | 例如 Adobe's ASCII85 |
将**Hello w0r1d!**进行base64 base32 base16分别编码后可得到:
SGVsbG8gdzByMWQh #base64
JBSWY3DPEB3TA4RRMQQQ==== #base32
48656C6C6F20773072316421 #base16
URL编码
URL 编码,也被称为百分号编码,是一种编码机制,其特点是编码后会包含大量的百分号。用于将不安全或特殊的字符转换为%后跟其 ASCII 的十六进制表示,以确保 URL 的安全传输。
通常的 url 编码只会处理符号和不可见字符,比如 Squdgy fez, blank jimp crwth vox
会被编码为 Squdgy%20fez%2C%20blank%20jimp%20crwth%20vox (普通类型)
但在 CTF 中我们可能会将其编码为
%53%71%75%64%67%79%20%66%65%7a%2c%20%62%6c%61%6e%6b%20%6a%69%6d%70%20%63%72%77%74%68%20%76%6f%78 (复杂类型)
甚至出现多次 Url 编码的情况,当然这可能存在一些恶趣味,但是在渗透过程中,多次 url 编码确实是一种有效的 Bypass 手段。
将**Hello w0r1d!**进行url编码后可得到:
%20Hello%20w0r1d%21 #普通类型
其他编码
这类编码相对没那么常见吧,可能,嗯可能。
原文本依旧为:Hello w0r1d!
- Unicode编码
共有四种编码方式:
\U [Hex]: \U0048\U0065\U006C\U006C\U006F\U0020\U0077\U0030\U0072\U0031\U0064\U0021
\U+ [Hex]: \U+0048\U+0065\U+006C\U+006C\U+006F\U+0020\U+0077\U+0030\U+0072\U+0031\U+0064\U+0021
&# [Decimal]: Hello w0r1d!
&#x [Hex]: Hello w0r1d!
- XXencode编码
AG4JgP4wURn-mAKEV
- UUencode编码
,2&5L;&\@=S!R,60A
- Escape/Unescape编码(编码感觉哪里怪怪的
- Quoted-printable编码(编码感觉哪里怪怪的
- HTML实体编码(编码感觉哪里怪怪的
- shellcode编码(编码感觉哪里怪怪的
- 摩尔斯电码Morse code
又被称为摩斯密码,是一种经典的编码方式
A .- N -. . .-.-.- + .-.-. 1 .----
B -... O --- , --..-- _ ..--.- 2 ..---
C -.-. P .--. : ---... $ ...-..- 3 ...--
D -.. Q --.- " .-..-. & .-... 4 ....-
E . R .-. ' .----. / -..-. 5 .....
F ..-. S ... ! -.-.-- 6 -....
G --. T - ? ..--.. 7 --...
H .... U ..- @ .--.-. 8 ---..
I .. V ...- - -....- 9 ----.
J .--- W .-- ; -.-.-. 0 -----
K -.- X -..- ( -.--.
L .-.. Y -.-- ) -.--.-
M -- Z --.. = -...-
以**Hello w0r1d!**为例,编码后得到:
.... . .-.. .-.. --- .-- ----- .-. .---- -.. -.-.--
- 敲击码Tap code
「 敲击码 Tap code 」是一种以非常简单的方式对文本信息进行编码的方法。因该编码对信息通过使用一系列的点击声音来编码而命名.
敲击码是基于 5×5 方格 波利比奥斯方阵 来实现的,不同点是是用 K 字母被整合到 C 中。
敲击码表如下:
1 2 3 4 5
1 A B C/K D E
2 F G H I J
3 L M N O P
4 Q R S T U
5 V W X Y Z
还是以**Hello w0r1d!**为例,编码后得到:
23 15 31 31 34 52 42 14
工具
CyberChef
CyberChef [https://cyberchef.cn/]是 CTF 中最常用的编码解码工具之一,内含多种编码和解码方式。
Ciphey
Ciphey 是一个全自动的解密/解码/爆破工具
随波逐流
[随波逐流]CTF 编码工具 由随波逐编写开发,CTF 编码工具为用户提供丰富的离线符编码进行转换,加密解密功能。
编码拓展
取证隐写
文件基础(前置技术)
简介
文件是信息的基本载体。无论是文本文档、图像、音频、还是可执行程序,每个文件都遵循特定的格式和结构,以便计算机系统能够正确识别、处理和呈现数据。
所有文件格式的本质都是二进制文件,这是易于计算机操作的进制格式,而对我们而言,我们时常使用 十六进制 对文件进行分析。
为了便于计算机识别,文件通常会包含除文件内容本身以外的一些特征标识,以ZIP文件为例:
Binary : 01010000 01001011 00000011 00000100
Hex : 50 4b 03 04
Hexdump: 50 4b 03 04 ........|PK..|
魔法数字Magic number
为了区分不同类型的文件,这里引入了一个概念:魔法数字,本质上他就是每个文件类型的 「 特征签名 File Signatures 」,不同文件类型的魔法数字不同,同类文件具备同样的魔法数字。
按照英文释义,特征签名又有: "File Magic number" 和 "File checksum or more generally the result of a hash function over the file contents" ,即 魔法数字 和 校验值。
上面例子中提到的 文件头 ,特指的"50 4b 03 04",而这里的 "50 4b 03 04" 就是ZIP压缩文件的 「 魔法数字 Magic number 」 特征签名 。
这种签名标识通常被放于头部,所以我们常用文件头来代指,严格的概念区分可以看下面关于三者的解释,但在实际中,我们不会做太严格的区分,用文件头来代指魔法数字也不会影响理解(这块后续可以深入了解一下)。
常用工具
- 010Editor
- Winhex
- Python
隐写技术
图片隐写
图像文件有多种复杂的格式,可以用于各种涉及到元数据、信息丢失和无损压缩、校验、隐写或可视化数据编码的分析解密,都是 Misc 中的一个很重要的出题方向。涉及到的知识点很多(包括基本的文件格式,常见的隐写手法及隐写用的软件),有的地方也需要去进行深入的理解。
PNG隐写
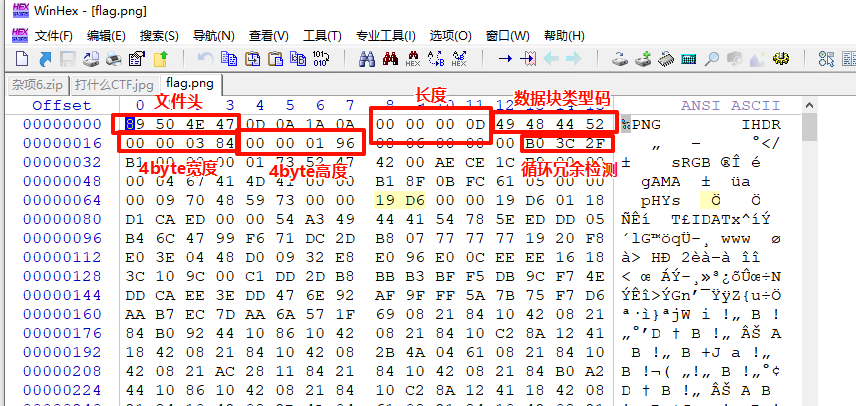
PNG文件的文件头由一个8字节的PNG文件标识域和3个以上的后续数据块,如IHDR、IDAT、IEND等组成
其标识如下:
89 50 4E 47 0D 0A 1A 0A +数据块+数据块+数据块
89:用于检测传输系统是否支持8位的字符编码,用以减少将文本文件被错误的识别成PNG文件的机会,反之亦然
50 4E 47:PNG每个字母对应的ASCII,让用户可以使用文本编辑器查看时,识别出是PNG文件
0D 0A:DOS风格的换行符,用于DOS-Unix数据的换行符转换
1A:在DOS命令行下,用于阻止文件显示的文件结束符
0A:Unix风格的换行符,用于Unix-DOS换行符的转换
可能遇到的隐写情况为:
- 文件格式修改(把PNG文件的后缀改成其他的文件)
- 文件格式倒转(文件的Hex值倒转排列,写脚本复原)
- 文件头缺失(用工具补齐)
- 修改图片宽高
PNG文件中,每个数据块都由四个部分组成,分别为:
长度(Length):指定数据块中数据区域的长度,长度不可超过(2^31-1)个字节
数据块类型码(Chunk Type Code):数据块类型码由ASCII字母(A-Z和a-z)组成的"数据块符号"
数据块数据(Chunk Data):存储数据块类型码指定的数据
循环冗余检测(CRC):存储用来检测是否文件传输有误的循环冗余码
修改对应的宽高位的数据即可
- CRC值爆破**(比较复杂,后续深入了解)**
https://blog.csdn.net/weixin_44145452/article/details/109612189
- 文件提取(用binwalk、foremost等工具提取)
JPG隐写
- JPEG 是有损压缩格式,将像素信息用 JPEG 保存成文件再读取出来,其中某些像素值会有少许变化。在保存时有个质量参数可在 0 至 100 之间选择,参数越大图片就越保真,但图片的体积也就越大。一般情况下选择 70 或 80 就足够了
- JPEG 没有透明度信息
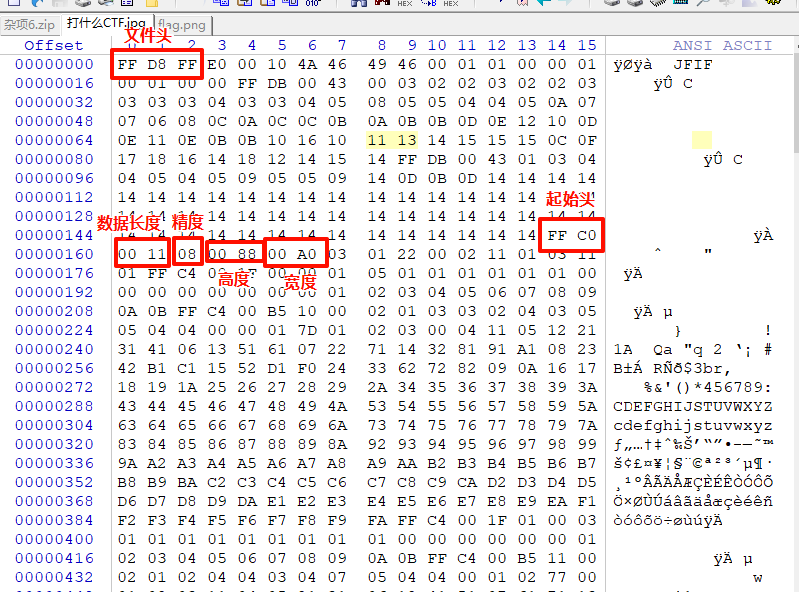
JPEG文件的文件头标识如下:
FF D8 FF
另外其文件尾标识为:
FF D9
可能遇到的隐写情况为:
- 修改图片宽高
修改对应的宽高位的数据即可
BMP隐写
BMP 文件格式能够存储单色和彩色的二维数字图像,具有各种颜色深度,并且可以选择使用数据压缩、alpha 通道和颜色配置文件
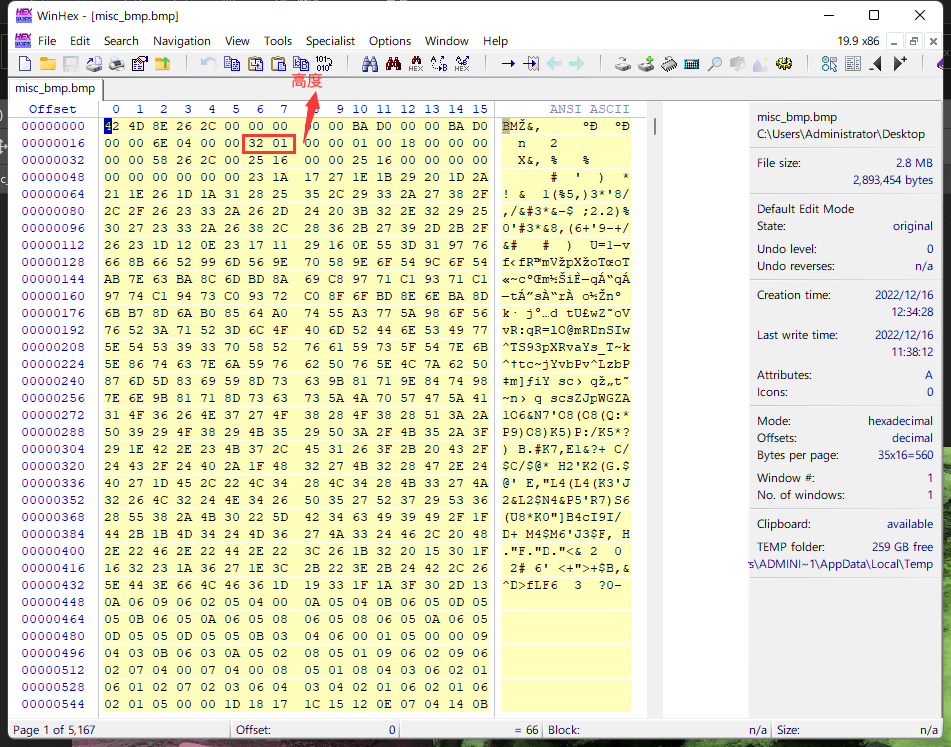
其文件头标识如下:
42 4D
BMP文件头标识的后四位表示的是BMP的图片大小,示例如下
8E 26 2C 00
由于个人计算机都是以小端序,所以数据要从右往左写
所以其大小实则应为
0x002c268e == 2893454(Byte) == 2.75M
可能遇到的隐写情况为:
- 修改图片宽高
EXIF信息
拍摄图片时,exif会记录数码照片的属性信息和拍摄数据,可以通过查看图片属性中的详细信息看到部分exif信息
在kali中可以使用exiftool查看更详细的exif数据
exiftool xxx.jpg
可能遇到的题型:
- OSINT(社工,查看图片经纬度)
GIF隐写
GIF的文件头标识如下:
47 49 46 38 39 61
可能遇到的题型如下:
- GIF帧分离+拼接
这类题型需要用到imagemagick工具
sudo apt install imagemagick
对于得到的gif,对它进行帧分离操作
convert xxx.gif xxx.png #逐帧分割图片
最后将得到的图片集群拼成一张图片
montage xxx*.png -tile x1 -geometry +0+0 xxx.png #合并图片
- GIF图像特征
有些gif图每帧间存在规律,可能每一帧的时间间隔隐藏了信息
可以用identify工具识别他的间隔
identify -format "%T" xxx.gif
最后将得到的值进行处理
- 逐帧查看
使用stegsolve工具进行逐帧分析
盲水印
显然这就是一种肉眼不可见的水印
需要使用bwm工具进行解析
bwm decode xxx.png xxx_with_wm.png yyy.png
LSB隐写
简单来说就是人眼无法区分所有的颜色,通过修改LSB(最低有效位),在改变少量数据达到隐藏信息的情况下,让人眼无法察觉到前后的变化,已达到隐写的目的,如下图所示。
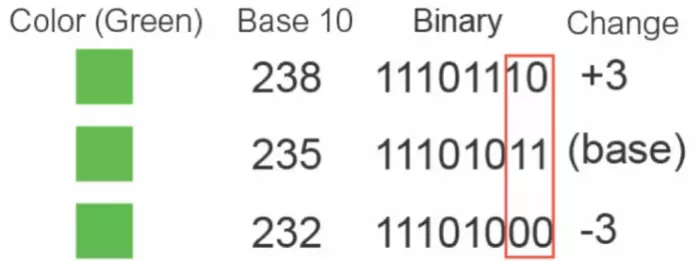
针对这类隐写,可能遇到以下类型:
-
工具分析(利用stegsolve)
-
数据隐藏(利用kali的lsb工具)
示例如下
lsb extract secret.png flag.txt 7his_1s_p4s5w0rd
//extract:提取,后面为需要提取信息的图片和输出的文件名,以及key值
字符串提取
有些题目会往图片里添加一些字符串,可以直接使用kali的strings工具提取
strings xxx.jpg
音频隐写
与音频相关的题目一般都是采取了隐写的策略
MP3隐写
利用Mp3Stego工具解密
decode.exe -X xxx.mp3 -P xxx # -P参数后需要输入密码
波形
通过软件观察音频的波形规律,将其转化为01字符串等,从而提取flag
频谱
音频中的频谱隐写是将字符串隐藏在频谱中,此类音频通常会有一个较明显的特征,听起来是一段杂音或者比较刺耳。直接查看音频的频谱图
LSB音频隐写
使用silenteye分析音频文件
流量取证
简介
流量分析与取证在 misc 中也是较为常见的题目,是一个非常重要的考察方向。该类型的题目往往会提供一个包含流量数据的PCAP文件,又通过一些处理后得到一个流量包数据文件,在进行分析。
其核心就在于如何分类和过滤数据,以便于快速定位问题流量
大方向上有以下步骤
- 总体把握
- 协议分级
- 端点统计
- 过滤赛选
- 过滤语法
- Host,Protocol,contains,特征值
- 发现异常
- 特殊字符串
- 协议某字段
- flag 位于服务器中
- 数据提取
- 字符串提取
- 文件提取
总的来说比赛中的流量分析可以概括为以下三个方向:
- 流量包修复
- 协议分析
- 数据提取
流量包修复
直接利用现成的工具修复:
pcapfix
https://f00l.de/hacking/pcapfix.php
协议分析
这里主要分析几个常见的协议
HTTP
HTTP ( Hyper Text Transfer Protocol ,也称为超文本传输协议) 是一种用于分布式、协作式和超媒体信息系统的应用层协议。 HTTP 是万维网的数据通信的基础。
HTTPS
HTTPs = HTTP + SSL / TLS. 服务端和客户端的信息传输都会通过 TLS 进行加密,所以传输的数据都是加密后的数据
FTP
FTP ( File Transfer Protocol ,即文件传输协议) 是 TCP/IP 协议组中的协议之一。 FTP 协议包括两个组成部分,其一为 FTP 服务器,其二为 FTP 客户端。其中 FTP 服务器用来存储文件,用户可以使用 FTP 客户端通过 FTP 协议访问位于 FTP 服务器上的资源。在开发网站的时候,通常利用 FTP 协议把网页或程序传到 Web 服务器上。此外,由于 FTP 传输效率非常高,在网络上传输大的文件时,一般也采用该协议。
默认情况下 FTP 协议使用 TCP 端口中的 20 和 21 这两个端口,其中 20 用于传输数据, 21 用于传输控制信息。但是,是否使用 20 作为传输数据的端口与 FTP 使用的传输模式有关,如果采用主动模式,那么数据传输端口就是 20 ;如果采用被动模式,则具体最终使用哪个端口要服务器端和客户端协商决定。
DNS
DNS 通常为 UDP 协议, 报文格式
+-------------------------------+
| 报文头 |
+-------------------------------+
| 问题 (向服务器提出的查询部分) |
+-------------------------------+
| 回答 (服务器回复的资源记录) |
+-------------------------------+
| 授权 (权威的资源记录) |
+-------------------------------+
| 额外的 (额外的资源记录) |
+-------------------------------+
查询包只有头部和问题两个部分, DNS 收到查询包后,根据查询到的信息追加回答信息、授权机构、额外资源记录,并且修改了包头的相关标识再返回给客户端。
每个 question 部分
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ QNAME /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QTYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| QCLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
QNAME:为查询的域名,是可变长的,编码格式为:将域名用. 号划分为多个部分,每个部分前面加上一个字节表示该部分的长度,最后加一个0字节表示结束QTYPE:占16位,表示查询类型,共有16种,常用值有:1(A记录,请求主机IP地址)、2(NS,请求授权DNS服务器)、5(CNAME别名查询)
WIFI
802.11 是现今无线局域网通用的标准, 常见认证方式
- 不启用安全
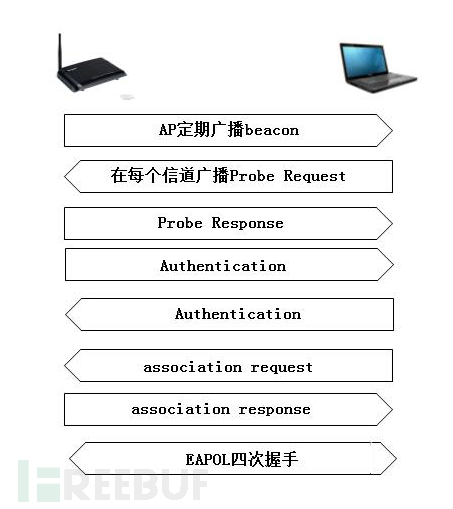
WEPWPA/WPA2-PSK(预共享密钥)PA/WPA2 802.1X(radius认证)
其中WPA-PSK的认证大致过程如下图
其中四次握手过程
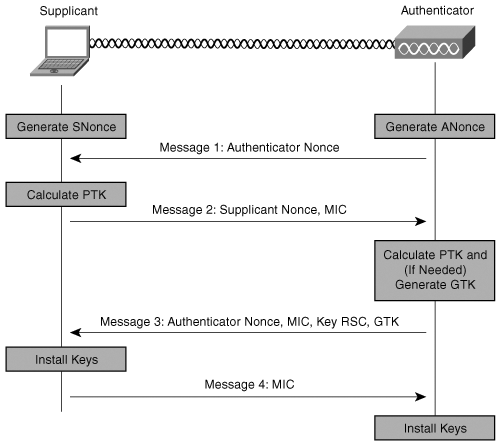
- 4 次握手开始于验证器 (AP),它产生一个随机的值(ANonce) 发送给请求者
- 请求者也产生了它自己的随机 SNonce,然后用这两个 Nonces 以及 PMK 生成了 PTK。请求者回复消息 2 给验证器, 还有一个 MIC(message integrity code,消息验证码)作为 PMK 的验证
- 它先要验证请求者在消息 2 中发来的 MIC 等信息,验证成功后,如果需要就生成 GTK。然后发送消息 3
- 请求者收到消息 3,验证 MIC,安装密钥,发送消息 4,一个确认信息。验证器收到消息 4,验证 MIC,安装相同的密钥
USB
这块比较复杂,后续详细分析
暂时需要知道一般以鼠标流量和键盘流量为主
Wireshark
数据提取
压缩包分析
简介
压缩包类题目一般分为zip和rar两种
ZIP
文件结构
一个ZIP文件由三个部分组成:
压缩源文件数据区
压缩源文件目录区
压缩源文件目录结束标志
RAR
文件结构
一个RAR文件由三个部分组成:
标记块和压缩文件头块
文件头块
结尾块
爆破
爆破就是通过最简单直接的方法暴力获取压缩包密码,适合密码较为容易或者知道密码范围/格式,包括字典爆破、掩码攻击等
主要利用现成的爆破工具实现
ARCHPR
Ziperello
fcrackzip
hashcat
伪加密
伪加密就是通过修改压缩文件的加密标志位,使得压缩文件在解压时不需要密码。
ZIP
zip类型的压缩包实现伪加密的原理是对其加密标识位进行修改
在了解了 ZIP 的构成以后可以发现识别一个 zip 文件是否加密主要是看压缩源文件数据的全局方式位标记和压缩源文件目录区的全局方式位标记,关键操作在其中的全局方式标记的第一字节数字的奇偶上,其它的不管为何值,都不影响它的加密属性。通常全局方式位标记为 2 bytes 长度,第一字节数字为偶数表示无加密,例如:00,02,04 等;为奇数表示有加密,例如 01,03,09 等。
无加密
无加密的 zip 压缩包压缩源文件数据区的全局加密应当为 00 00,且压缩源文件目录区的全局方式位标记也为 00 00。
真加密
真加密的 zip 压缩包压缩源文件数据区的全局加密应当为 09 00,且压缩源文件目录区的全局方式位标记也为 09 00。
伪加密
伪加密的 zip 压缩包压缩源文件数据区的全局加密应当为 09 00,且压缩源文件目录区的全局方式位标记也为 00 00 或者 01 00。
处理方法:
- binwalk -e分离
- 个别解压工具可直接解压(360)
- 修改文件标识位
- 在
MacOS和部分Linux(如kali)系统重,可以直接打开 - 检测伪加密的小工具
ZipCenOp.jar
RAR
RAR 文件的伪加密在文件头中的位标记字段上,修改这一位可以造成伪加密。
明文攻击
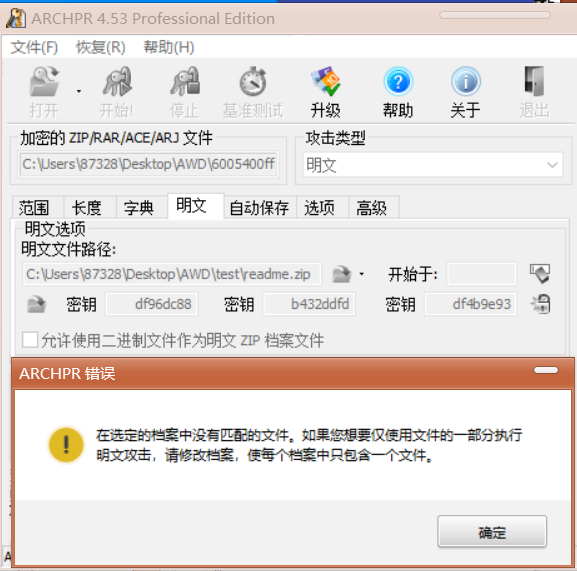
明文攻击就是在已有一个真加密的压缩包内的其中一个文件,而我们需要解压得到其他加密文件时,可以利用这个已知已有的文件,对压缩包进行攻击。原理主要是利用了压缩算法一致阿巴巴巴
攻击步骤如下:
- 将得到的明文文件压缩成一个压缩包
- 利用工具或指令,在明文文件压缩包的基础上对加密文件进行明文攻击
需要注意的是,需要保证明文文件的压缩方式与加密文件是相同的(或者说要是用同一个压缩软件压缩的),否则可能会有以下报错
CRC32碰撞
CRC 本身是「冗余校验码」的意思,CRC32 则表示会产生一个 32 bit ( 8 位十六进制数) 的校验值。由于 CRC32 产生校验值时源数据块的每一个 bit (位) 都参与了计算,所以数据块中即使只有一位发生了变化,也会得到不同的 CRC32 值。
CRC32 校验码出现在很多文件中比如 png 文件,同样 zip 中也有 CRC32 校验码。值得注意的是 zip 中的 CRC32 是未加密文件的校验值。
这也就导致了基于 CRC32 的攻击手法。
- 文件内内容很少 (一般比赛中大多为
4字节左右) - 加密的密码很长
我们不去爆破压缩包的密码,而是直接去爆破源文件的内容 (一般都是可见的字符串),从而获取想要的信息。
可以通过编写对应的脚本去进行爆破(后续跟进)
磁盘内存分析
简介
内存取证在 ctf 比赛中也是常见的题目,内存取证是指在计算机系统的内存中进行取证分析,以获取有关计算机系统当前状态的信息。内存取证通常用于分析计算机系统上运行的进程、网络连接、文件、注册表等信息,并可以用于检测和分析恶意软件、网络攻击和其他安全事件
一般来说,我们获取到的都是已经提取好的内存镜像文件,只需要直接对其进行分析取证即可,内存镜像文件一般为raw文件
常用工具
- Volatility2/3
- Elcomsoft Forensic Disk Decryptor(EFDD)
- FTK
- EasyRecovery
- MedAnalyze
磁盘
常见的磁盘分区格式有以下几种
-
Windows: FAT12 -> FAT16 -> FAT32 -> NTFS
-
Linux: EXT2 -> EXT3 -> EXT4
-
FAT 主磁盘结构

-
删除文件:目录表中文件名第一字节
e5。
VMDK
VMDK 文件本质上是物理硬盘的虚拟版,也会存在跟物理硬盘的分区和扇区中类似的填充区域,我们可以利用这些填充区域来把我们需要隐藏的数据隐藏到里面去,这样可以避免隐藏的文件增加了 VMDK 文件的大小(如直接附加到文件后端),也可以避免由于 VMDK 文件大小的改变所带来的可能导致的虚拟机错误。而且 VMDK 文件一般比较大,适合用于隐藏大文件。
内存
- 解析 Windows / Linux / Mac OS X 内存结构
- 分析进程,内存数据
- 根据题目提示寻找线索和思路,提取分析指定进程的特定内存数据
取证分析过程
主要以volatility对内存文件进行分析为主,以下主要介绍他的使用
(后续补上)
anyway,我找了个还算好用的内存取证项目,可以直接拿来分析↓
https://github.com/Tokeii0/LovelyMem
其他
pyc
后续补充


