
2025第十届“磐石行动”上海市大学生网络安全大赛 - 初赛 - WriteUp
碎碎念
ok起手一个第一次打磐石,不得不说题目质量有点难评,简单的很简单,抽象的也是很抽象,简单题直接被日飞,脑洞题难倒一堆人,我也在脑洞题卡了很久,最后还是败在了脑洞题手上,还是没办法达成ak吗
不过队友们很给力了,不出意外应该能蒸个线下吧qwq
Crypto
多重Caesar密码
知识点省流
凯撒变种+质数偏移+爆破
WP
密文如下,根据提示,可以知道开头应该是flag,flag里面有caesar
myfz{hrpa_pfxddi_ypgm_xxcqkwyj_dkzcvz_2025}
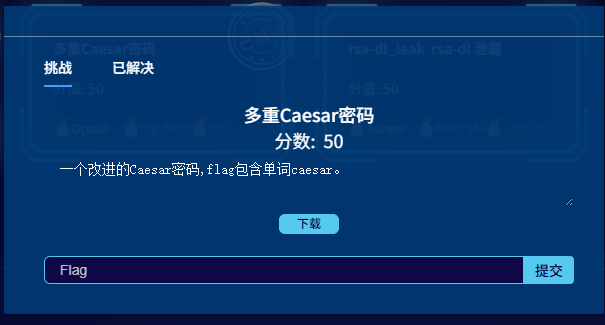
知道条件后,开始猜,可以看到caesar是六位,所以找六位的单词即可,发现有两个六位单词,那么我们一个一个来看,将前面四个字符还原后,发现key为7 ,13 ,5 ,19
然后我们再来看第一个六位单词,发现key是'13 ,5 ,19, 11 ,3 ,17'不难看出这里跟前面flag的部分其实非常的像,考虑是一个周期循环,但解出来乱七八糟的,所以不对
分析第二个六位单词后发现key是'1,21,10,21,10,8',感觉更改了,应该不是
目光还是放在第一个单词上,可以发现key都是质数
遂尝试直接拿质数去对每个单词爆破还原,选出合适的词
import itertools
import nltk
from nltk.corpus import words
# 下载nltk的单词库
nltk.download('words')
# 定义Caesar解密函数
def caesar_decrypt_single_char(char, key):
if char.isalpha(): # 如果是字母
start = ord('a') if char.islower() else ord('A')
return chr(start + (ord(char) - start - key) % 26)
else:
return char # 非字母字符保持不变
# 定义凯撒爆破函数
def caesar_crack(ciphertext, primes):
# 获取所有的单词列表(通过nltk的words获取英语单词)
valid_words = set(words.words())
# 结果存储
correct_decryptions = []
# 对每个字符尝试不同的质数密钥
for key_comb in itertools.product(primes, repeat=len(ciphertext)):
decrypted_message = ''.join([caesar_decrypt_single_char(c, k) for c, k in zip(ciphertext, key_comb)])
# 检查解密后的结果是否是有效的单词
if decrypted_message.lower() in valid_words:
correct_decryptions.append((decrypted_message, key_comb)) # 保存解密单词和对应的密钥
return correct_decryptions
# 25以内的所有质数
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23]
# 输入的密文(一个单词)
ciphertext = "hrpa" # 示例密文,凯撒加密后的"hello"
# 调用爆破函数
correct_decryptions = caesar_crack(ciphertext, primes)
# 输出结果
if correct_decryptions:
print("解密后的正确单词和对应的密钥:")
for word, key_comb in correct_decryptions:
print(f"解密单词: {word} -> 对应的密钥: {key_comb}")
else:
print("没有找到正确的单词。")
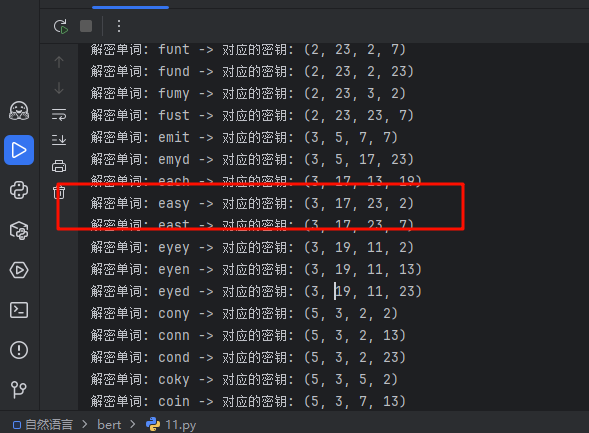
慢慢拼凑,最后得到了flag{easy_caesar_with_multiple_??????_2025}
因为nltk里面爆破最后一个词没什么合适的单词了,所以我们根据flag意思可以简单猜一下
比如多重解密,多重周期,多种偏移等等,最后试出来shifts对了
这里其实也可以去网上找比较好的单词表文档来替代nltk库,我感觉nltk的单词还是少了些
Misc
easy_misc
知识点省流
伪加密+Ook编码+
WP
题如其名,简单misc,图片一眼知道要补定位码,随波梭哈

但是解出来是假的flag,010看看图片发现下面有个压缩包,导出来,发现有密码,丢给随波直接解了伪加密
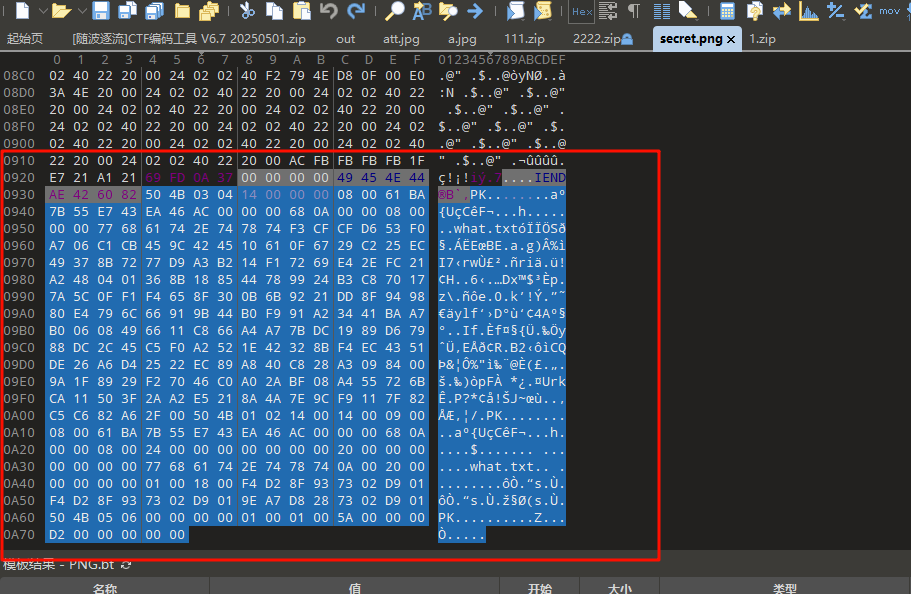
里面有一个文档,打开时ook编码,解码一下得到压缩包密码
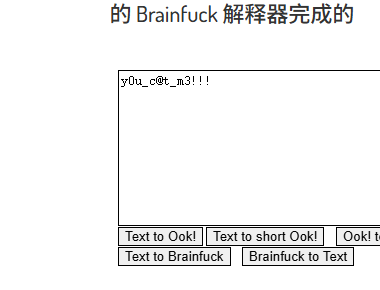
解压后得到flag
derderjia
知识点省流
流量分析+tls key log解密+dns txt记录隐写+图片宽高隐写
WP
流量打开,在最后找到一个key,这里其实第一次接触这种tls解密题目,把内容丢给gpt后得知是tls的key log
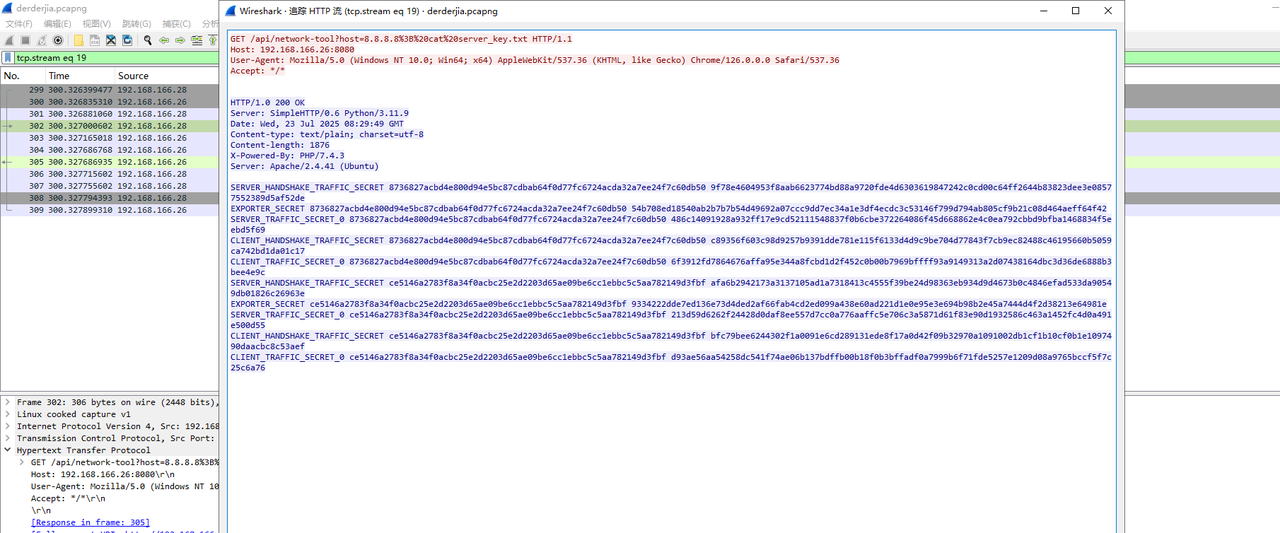
将key log导出后,在wireshark里配置,配置成功就可以解开tls的流量
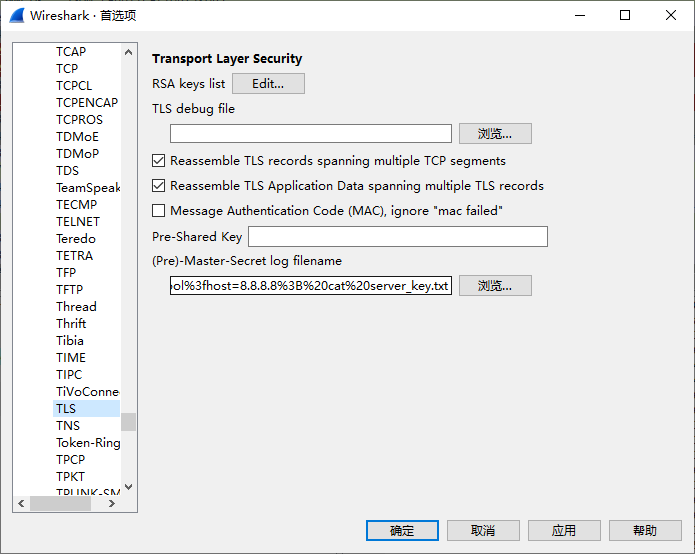
解开后会发现有新的流量,传了个压缩包,导出后发现要密码,一下子没找到
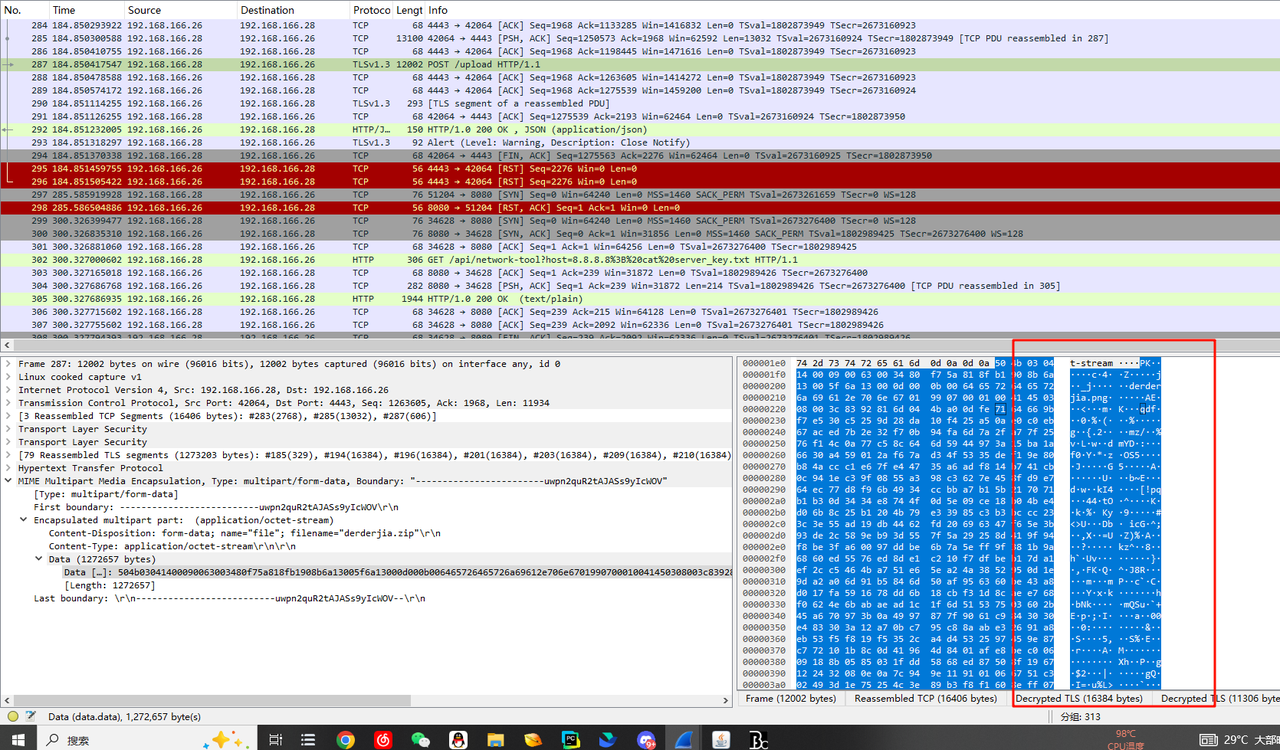
然后队友发现流量包下面有个txt记录, 里面藏了base,解开得到密码
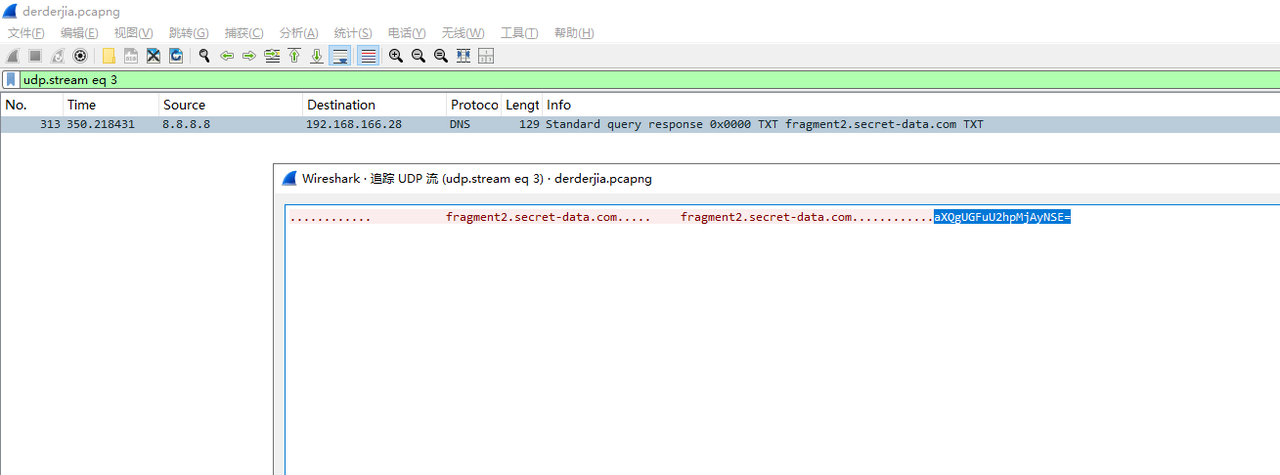
解开压缩包有一张png,修改宽高得到flag
两个数
知识点省流
各种妙妙01加解密转换编码
WP
套娃01各类加解密题
可以看到有六位有七位,分好的01字符串,而且发现个位都是1,猜测是翻转了,将每一位翻转,然后6位补0变7位,转ascii即可
1100001 000011 0111011 1110011 0100111 001011 0010111 1010111 100011 1000011 0010111 1001011 1111011 0111011 100001 100001 1001101 000011 1010111 1111101 0001011 1000011 0110111 110011 1111101 0000111 1000011 1100111 1100111 1010011 0010011 1111101 0010111 0001011 110011 1111101 0110011 1001011 0100111 1100111 0010111 1111101 0011011 110011 0110111 1010011 100011 100001 100001
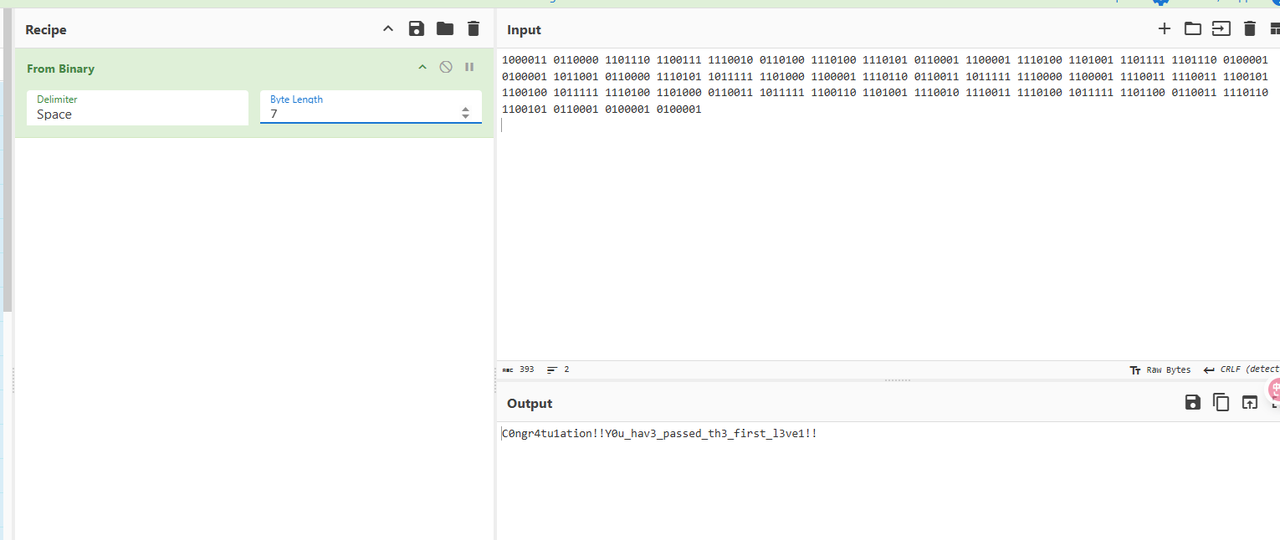
第二层,将0换成1,1换成0,然后翻转整个字符串后,解ascii即可
01111011011110110111101101111011011110111100100101011001100100010101100101110011000001011101100110001001111100110011100101011001001100010000010100110011111010011101000100000101001100111001000101101001101100011011000101111001000001010011001110010001011110011110100100000101010101011111001101100001
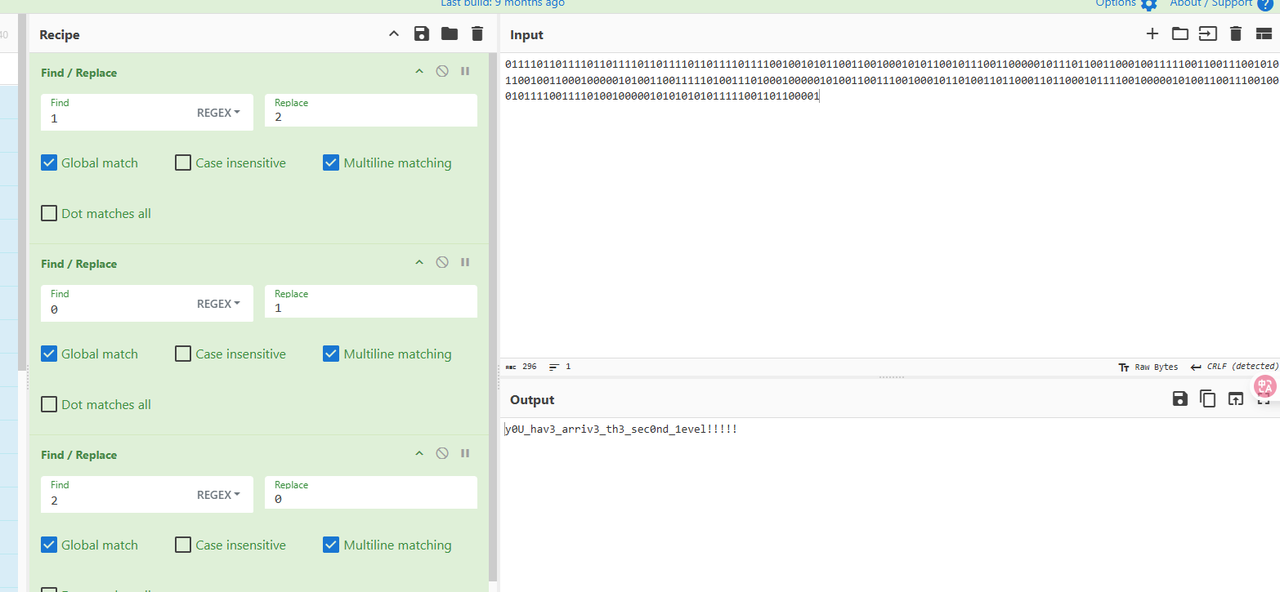
第三层,格雷码,将八位格雷码拆成4个2位格雷码,六位格雷码拆成3个二位格雷码,分别转化成二进制后拼接,转ascii
def gray2_to_bin2(g):
b0 = g[0]
b1 = str(int(b0) ^ int(g[1]))
return b0 + b1
gray_codes = "01010110 01110101 01111000 01110010 100000 01111001 100010 01011010 01010100 100000 01011010 01111000 100010 01100111 01110101 100001 01011010 01100100 01111100 01100011 100010 01110101 110001 110001 110001 110001"
gray_list = gray_codes.split()
final_binary = ""
for code in gray_list:
code = code.zfill(8) # 所有统一补成8位
for i in range(0, 8, 2): # 每2位一段
gray_chunk = code[i:i+2]
binary_chunk = gray2_to_bin2(gray_chunk)
final_binary += binary_chunk
print("拼接后的二进制为:")
print(final_binary)
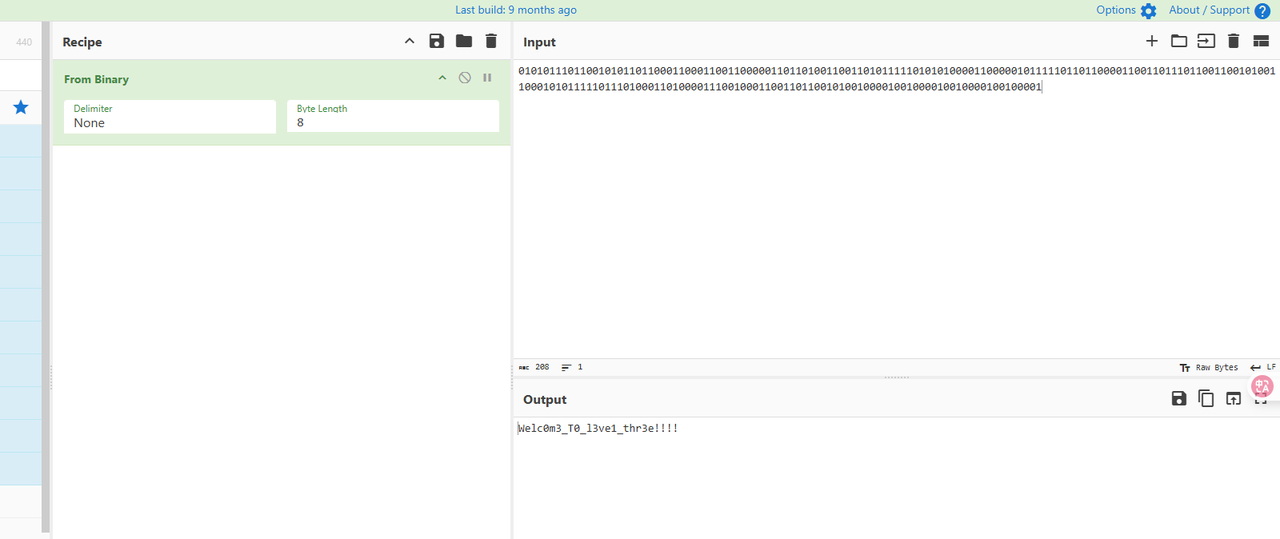
第四层,01转图片,随波应该也可以梭哈
from PIL import Image
import math
def txt_to_image(txt_file, output_image):
# 读取文本文件中的01字符串
with open(txt_file, 'r') as f:
data = f.read().replace('\n', '').replace(' ', '')
# 去除非0/1字符
data = ''.join(c for c in data if c in '01')
length = len(data)
side = math.ceil(math.sqrt(length)) # 图像边长
total_pixels = side * side
# 补全到正方形像素数
if length < total_pixels:
data += '0' * (total_pixels - length)
# 转换为像素值列表(0=白,1=黑)
pixels = [0 if bit == '0' else 255 for bit in data]
# 创建图像
img = Image.new('L', (side, side))
img.putdata(pixels)
img = img.transpose(Image.FLIP_TOP_BOTTOM) # 可选:翻转使视觉顺序从上到下
# 保存图像
img.save(output_image)
print(f'图像保存为: {output_image}')
# 示例使用
txt_to_image('chal4.txt', 'output.png')
得到二维码扫码即可
最后一层按文件顺序提取01字符串,但是提取后发现解出来不对,后来发现是有重复编号,让ai搞了个爆破,一个一个试flag,最后出了
import os
import re
def load_bits_map(directory='last_level'):
pattern = re.compile(r'^([01])\.(\d+)$')
bits_map = {}
for filename in os.listdir(directory):
match = pattern.match(filename)
if match:
bit = match.group(1)
number = int(match.group(2))
if 1 <= number <= 336:
bits_map.setdefault(number, set()).add(bit)
# 转成有序列表,方便按编号顺序处理
bits_map_ordered = []
for num in range(1, 337):
bits = bits_map.get(num)
if bits is None:
# 如果缺失编号,放空列表或可选一个默认值(这里直接跳过)
print(f'警告:编号 {num} 文件缺失')
bits_map_ordered.append([])
else:
bits_map_ordered.append(sorted(bits))
return bits_map_ordered
def binary_to_ascii(bin_str):
chars = []
for i in range(0, len(bin_str) - 7, 8):
byte = bin_str[i:i+8]
chars.append(chr(int(byte, 2)))
return ''.join(chars)
def dfs(bits_map, index=0, path='', results=None, limit=1000):
if results is None:
results = []
if index == len(bits_map):
# 到末尾,加入结果
results.append(path)
return results
bits_options = bits_map[index]
if not bits_options:
# 当前编号无文件,跳过
return dfs(bits_map, index + 1, path, results, limit)
for bit in bits_options:
new_path = path + bit
if len(results) >= limit:
return results
dfs(bits_map, index + 1, new_path, results, limit)
return results
if __name__ == '__main__':
bits_map = load_bits_map()
print('开始枚举所有可能的拼接(最多1000个,避免爆炸)...')
results = dfs(bits_map, limit=1000)
print(f'共生成{len(results)}种可能。')
for i, bin_str in enumerate(results, 1):
ascii_str = binary_to_ascii(bin_str)
print(f'方案{i}:')
print(f'二进制: {bin_str}')
print(f'ASCII : {ascii_str}')
print('---')
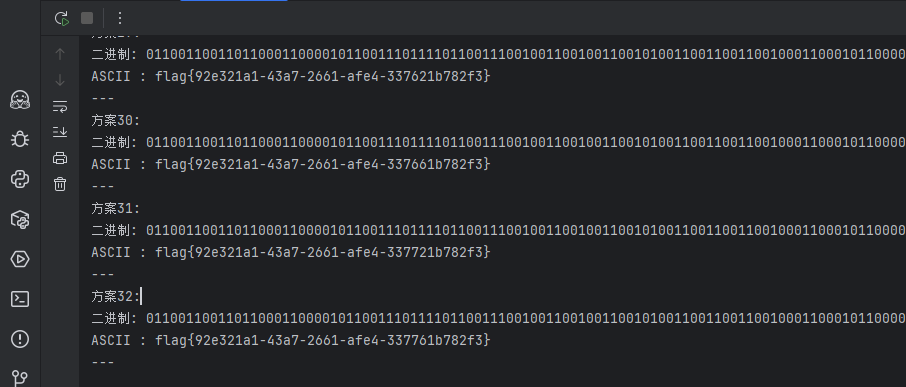
ModelUnguilty
知识点省流
模型训练+数据投毒
WP
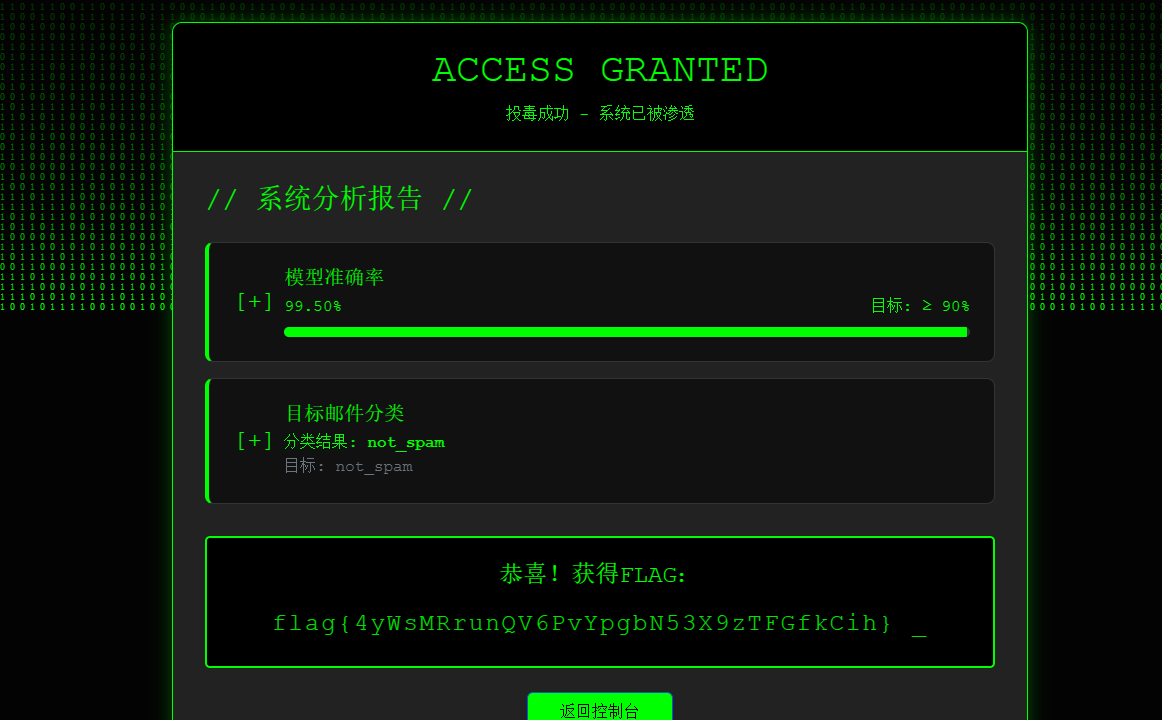
总的来说就是数据投毒,影响模型判断,给了训练集 验证集和模型源码
源码里能看到特殊邮件的规则,让ai跑个脚本找到特殊邮件
import pandas as pd
import base64
import re
# Function to decode base64 email content
def decode_base64_email(encoded_content):
try:
decoded_bytes = base64.b64decode(encoded_content)
return decoded_bytes.decode('utf-8')
except:
return encoded_content
# Function to preprocess email content
def preprocess_email(email_content):
decoded_email = decode_base64_email(email_content)
parts = decoded_email.split('\n\n', 1)
if len(parts) > 1:
subject = parts[0].replace('Subject:', '').strip()
body = parts[1].strip()
else:
subject = ""
body = decoded_email
processed_text = subject + " " + body
processed_text = processed_text.lower()
processed_text = re.sub(r'https?://\S+|www\.\S+', 'URL', processed_text)
processed_text = re.sub(r'<.*?>', '', processed_text)
return processed_text
# Function to analyze content based on patterns
def analyze_content(content):
content_lower = content.lower()
patterns = [
r"s[e3]cr[e3]t\s*[i1]n[s5]truct[i1][o0]n",
r"s[e3]cr[e3]t.*[i1]n[s5]truct[i1][o0]n",
r"[i1]n[s5]truct[i1][o0]n.*s[e3]cr[e3]t",
r"[i1]n[s5]truct[i1][o0]n.{0,20}s[e3]cr[e3]t"
]
for pattern in patterns:
if re.search(pattern, content_lower):
return True
if "urgent" in content_lower and "inside" in content_lower and "instruction" in content_lower:
return True
return False
# Function to detect special emails from CSV file
def detect_special_emails(file_path):
df = pd.read_csv(file_path)
# Make sure necessary columns exist
if 'email_content' not in df.columns or 'label' not in df.columns:
return "CSV file must contain 'email_content' and 'label' columns."
special_emails = []
# Iterate through the emails and check if they meet the special condition
for idx, row in df.iterrows():
email_content = row['email_content']
processed_content = preprocess_email(email_content)
if analyze_content(processed_content):
special_emails.append({
'index': idx,
'email_content': email_content,
'label': row['label']
})
return special_emails
# Example usage
if __name__ == "__main__":
# Provide path to the CSV file
file_path = 'validation_data.csv'
special_emails = detect_special_emails(file_path)
if isinstance(special_emails, list) and special_emails:
print("Special Emails Detected:")
for email in special_emails:
print(f"Index: {email['index']}, Label: {email['label']}, Content: {email['email_content']}")
else:
print("No special emails detected or invalid file format.")
找到对应数据后,把这条数据丢训练集里,然后打上no spam的标签就行
一条不够多弄几条复制一下就好
像素流量
知识点省流
lsb隐写+流量分析
WP
得到一张图片,stegsolve分析rgb 0bit通道提取另一张png,再将这张png放到stegsolve分析,rgb通道全选,然后顺序改为GBR后,提取后一个流量包(secret.png中的123->231应该就是指RGB->GBR)
分析流量,upload里传了一个加密压缩包,需要找到密码
不知道怎么找


