碎碎念
本题为今年阿里CTF的一道热身赛题,也是唯一一道,正好是道Misc,刷群的时候看到有就来看了,总体来说难度不高,但也学到了一些思路 由于截止到该wp发出时热身赛的奖品已经被领完了,并且我已征求赛事工作人员的许可,遂将该WP发到博客
正文
知识点省流
IDAT块隐写 音频隐写(音频频率字节转换)
WP
附件给的是一张png图片,直接看最后发现有一个异常IDAT块,被改成了F14G块,而且数据段为zlib数据,显然是zlib压缩的idat块隐写处理
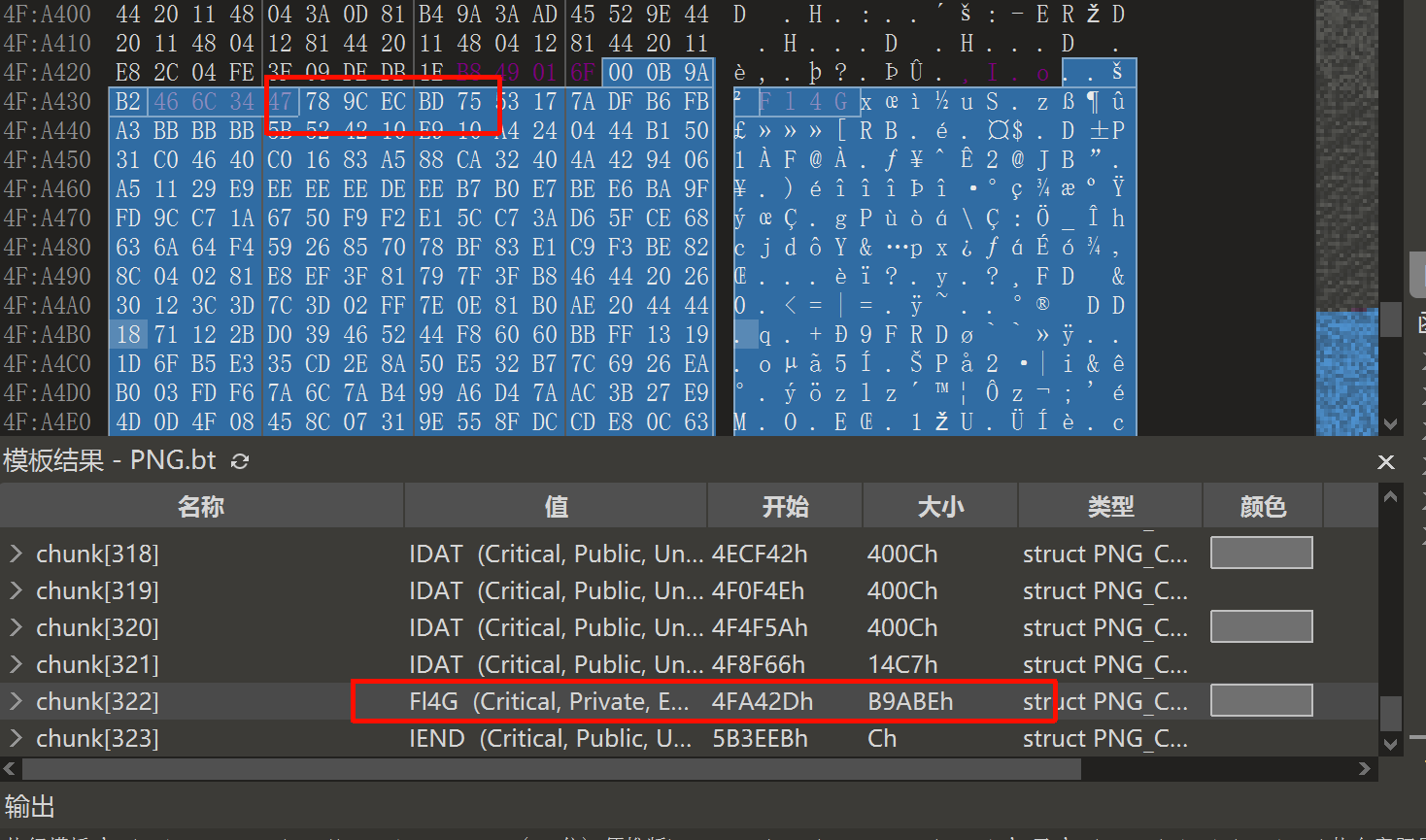
用厨子简单解压一下,会发现这是个wav音频 ,保存一下
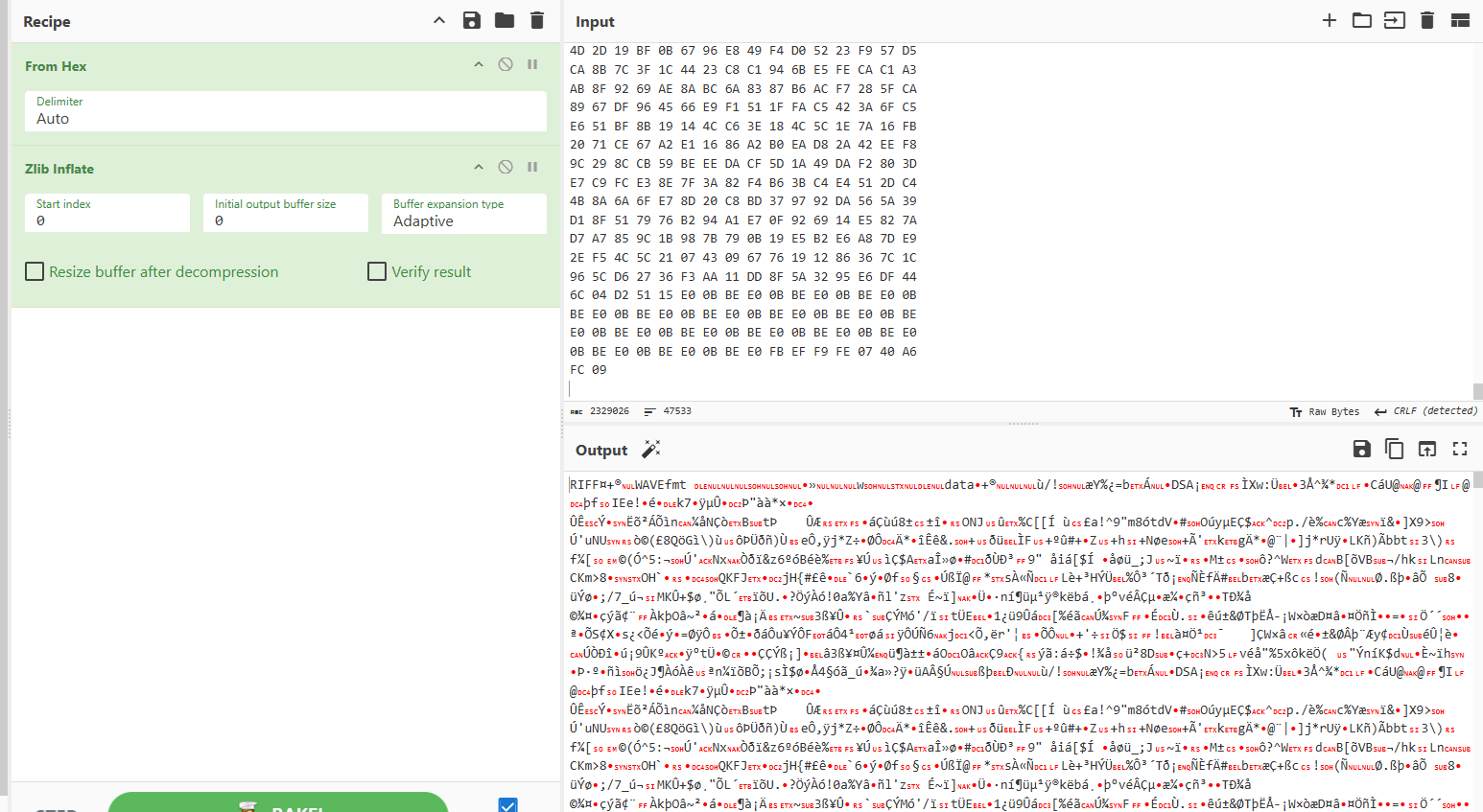
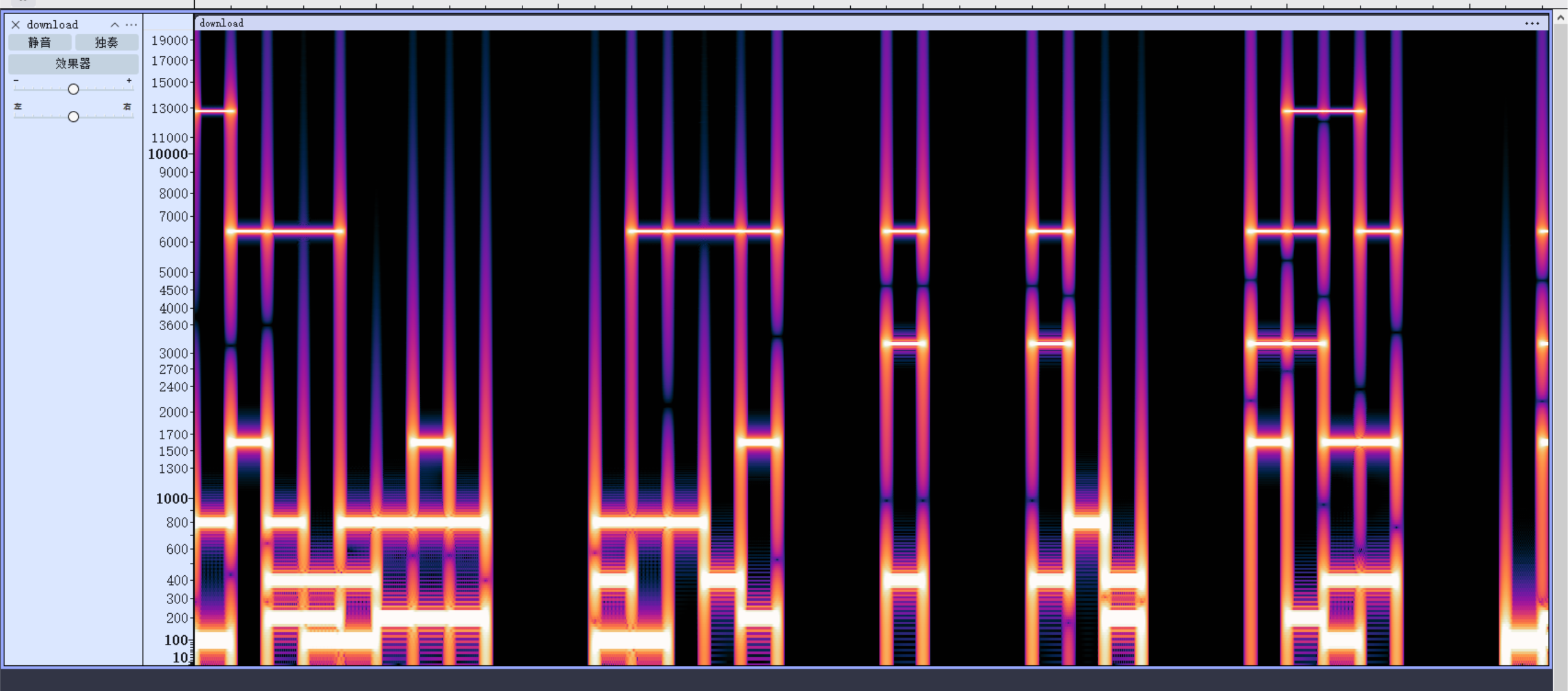
用audacity简单看看,发现他的音频非常的诡异,打开频谱图会发现每段里面有n个频率,但频率的大小似乎是固定的几种
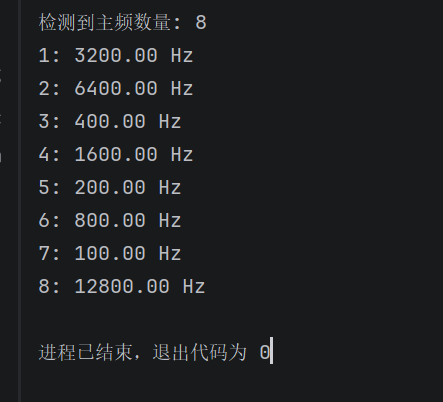
先让ai写个脚本检测一下主频率都有哪几种,分别是多少:
1import numpy as np
2import scipy.io.wavfile as wav
3from scipy.signal import find_peaks
4
5def analyze_main_frequencies(wav_path, min_height_ratio=0.1, min_distance_hz=20):
6 # 读取 wav
7 fs, data = wav.read(wav_path)
8
9 # 如果是立体声,取平均变单声道
10 if data.ndim == 2:
11 data = data.mean(axis=1)
12
13 # 转为 float 并去直流分量
14 data = data.astype(np.float64)
15 data = data - np.mean(data)
16
17 N = len(data)
18
19 # FFT
20 fft_vals = np.fft.rfft(data)
21 magnitudes = np.abs(fft_vals)
22 freqs = np.fft.rfftfreq(N, d=1/fs)
23
24 # 设定阈值:最大幅值的 min_height_ratio
25 height_threshold = magnitudes.max() * min_height_ratio
26
27 # 最小峰间距(转换为点数)
28 freq_resolution = fs / N
29 min_distance_bins = int(min_distance_hz / freq_resolution)
30
31 # 找峰值
32 peaks, properties = find_peaks(magnitudes, height=height_threshold, distance=min_distance_bins)
33
34 main_freqs = freqs[peaks]
35 main_mags = magnitudes[peaks]
36
37 # 按幅值排序
38 order = np.argsort(main_mags)[::-1]
39 main_freqs = main_freqs[order]
40 main_mags = main_mags[order]
41
42 return main_freqs, main_mags
43
44if __name__ == "__main__":
45 freqs, mags = analyze_main_frequencies("1.wav", min_height_ratio=0.1, min_distance_hz=20)
46
47 print(f"检测到主频数量: {len(freqs)}")
48 for i, f in enumerate(freqs, 1):
49 print(f"{i}: {f:.2f} Hz")发现一共就8种主频率,而且都呈现倍数关系,显然是刻意设计的
而且既然数量正好是8个,并且音频进行了分段划分,其实简单猜测可以联想到八位二进制,通过不同的频率表达不同的位
(问一下ai也能出)

紧接着写脚本去转换字节流即可,这里可以调教一下ai,给出脚本,不过需要注意引导ai完善
最终的exp如下,其中需要注意要把数据转换完全,保留静音的部分,将静音部分视为00,不然提取出来的文件是不全的
1import numpy as np
2from scipy.io import wavfile
3
4# --- 核心配置 ---
5FILENAME = '1.wav'
6OUTPUT_NAME = 'decoded_fixed.png'
7FRAME_SIZE = 4800
8# 频率表:从低位(Bit 0)到高位(Bit 7)
9TARGET_FREQS = [100, 200, 400, 800, 1600, 3200, 6400, 12800]
10
11
12def recover_file():
13 print(f"正在读取 {FILENAME} ...")
14 sample_rate, data = wavfile.read(FILENAME)
15
16 # 归一化处理
17 if len(data.shape) > 1: data = data[:, 0]
18 data = data.astype(np.float32)
19 max_val = np.max(np.abs(data))
20 if max_val > 0:
21 data /= max_val
22
23 total_samples = len(data)
24 print(f"总样本数: {total_samples}")
25
26 # 1. 寻找起始点 (Sync)
27 # PNG文件的开头是 0x89 (10001001),肯定有声音,所以寻找第一个非静音处作为起点是安全的
28 start_index = 0
29 threshold = 0.2 # 信号起始判定的阈值
30
31 for i in range(0, total_samples - FRAME_SIZE, 100): # 粗略扫描
32 # 检查这一小段的能量
33 if np.max(np.abs(data[i:i + 1000])) > threshold:
34 # 找到大致位置后,回退一点确保包含完整帧,这里简单处理直接对齐
35 # 为了更精准,通常第一个帧的能量会瞬间跳变
36 start_index = i
37 print(f"锁定起始采样点: {start_index}")
38 break
39
40 # 2. 强制解码直到文件末尾
41 raw_bytes = []
42
43 # 使用保护间隔,只分析帧中间的波形,避免边缘噪声
44 guard = 400
45
46 print("开始解码,不跳过任何静音帧...")
47
48 # 循环条件:只要还有完整的帧就继续读
49 for i in range(start_index, total_samples - FRAME_SIZE, FRAME_SIZE):
50 chunk = data[i:i + FRAME_SIZE]
51
52 # 取中间段进行FFT分析
53 analysis_chunk = chunk[guard:-guard]
54 # 加窗
55 windowed = analysis_chunk * np.hanning(len(analysis_chunk))
56
57 fft_data = np.abs(np.fft.rfft(windowed))
58 freqs = np.fft.rfftfreq(len(analysis_chunk), 1 / sample_rate)
59
60 byte_value = 0
61 local_max = np.max(fft_data)
62
63 # 即使 local_max 很小(静音),也说明这可能是一个 0x00 字节
64 # 只有当确实有明显频率峰值时才置位
65
66 # 这里的判定阈值稍微敏感一点,防止漏掉弱信号
67 # 如果整帧最大能量都极低,说明是 0x00,直接跳过频率检测循环
68 if local_max > 0.05:
69 for bit_idx, f_target in enumerate(TARGET_FREQS):
70 idx = np.argmin(np.abs(freqs - f_target))
71 # 检查该频率是否有能量峰值
72 # 判定标准:该频率幅值 > 当前帧最大幅值的 30%
73 if fft_data[idx] > local_max * 0.3:
74 byte_value |= (1 << bit_idx)
75
76 # 【关键修正】:无论 byte_value 是什么(包括0),都加入结果
77 raw_bytes.append(byte_value)
78
79 # 3. 保存与检查
80 print(f"解码结束,共提取 {len(raw_bytes)} 字节。")
81
82 byte_arr = bytearray(raw_bytes)
83
84 # 尝试自动修剪头部垃圾数据
85 png_header = b'\x89PNG'
86 head_pos = byte_arr.find(png_header)
87
88 if head_pos != -1:
89 print(f"在位置 {head_pos} 发现 PNG 头,自动修剪头部...")
90 byte_arr = byte_arr[head_pos:]
91 else:
92 print("警告:未自动发现 PNG 头,将保存所有提取数据,请手动检查。")
93 # 如果没找到头,有可能是起始点找晚了,导致错位。
94 # 这种情况下,不要截断,直接保存全部数据。
95
96 with open(OUTPUT_NAME, 'wb') as f:
97 f.write(byte_arr)
98
99 print(f"文件已保存: {OUTPUT_NAME}")
100 print("提示:如果图片下方显示不全,说明音频还没录完就断了,或者解码未到最后。")
101
102
103if __name__ == "__main__":
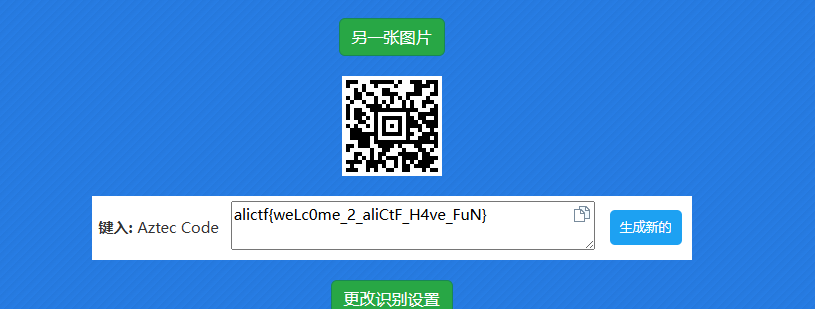
104 recover_file()最后可以得到一张png图片,里面是aztec码
在线扫一下就可以得到flag了
Comments will be available soon.