碎碎念
本来是想看看题的,因为那会刚打完iscc实在是太伤了。但结果看到有实体奖品,最后还是燃尽了…… 这比赛我只能说,怎么也算半个iscc了,有些题目出的真的抽象,完全get不到作者脑洞,告白更是一绝,不好评价。 但他又给贴纸又有奖品,真是人民的好比赛)
音频的秘密
附件得到一个音频,丢给audacity可以看到里面有摩斯密码,但是转出来发现信息是假的,丢给silenteye后设置为low发现藏了个压缩包
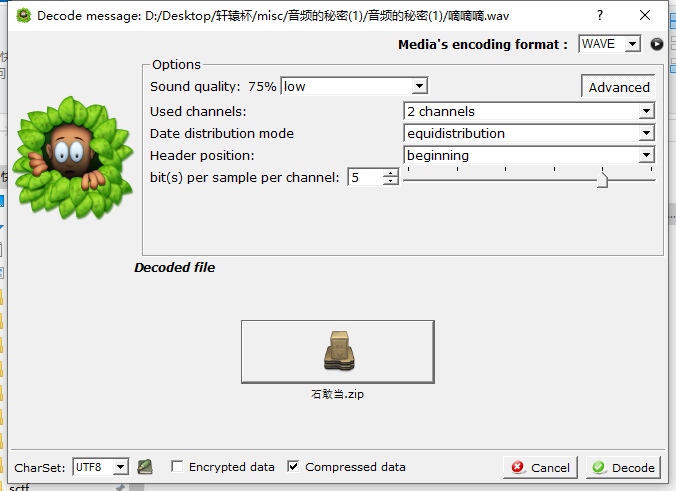
压缩包有密码,直接爆破,得到密码为1234
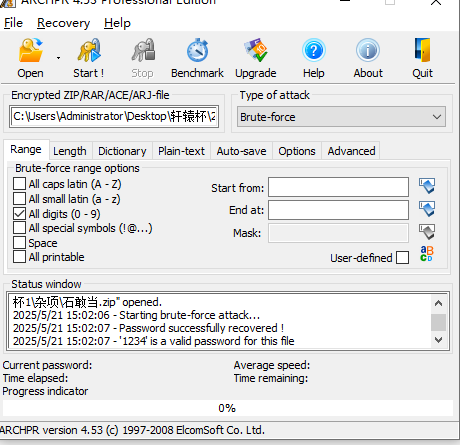
同时压缩包里有备注,给了个key为Lovely

解压得到的照片丢给随波,发现有lsb隐写
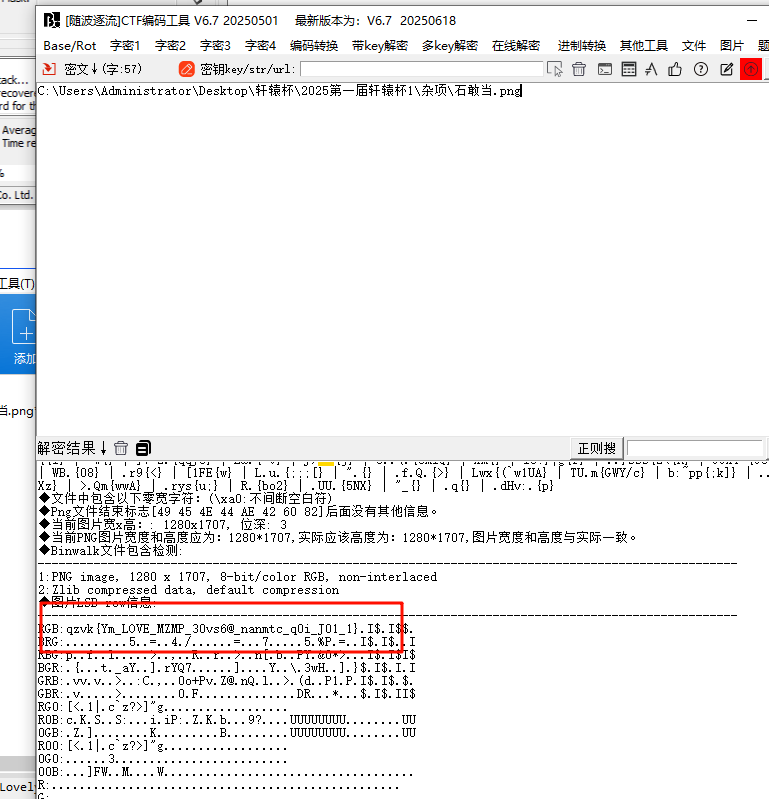
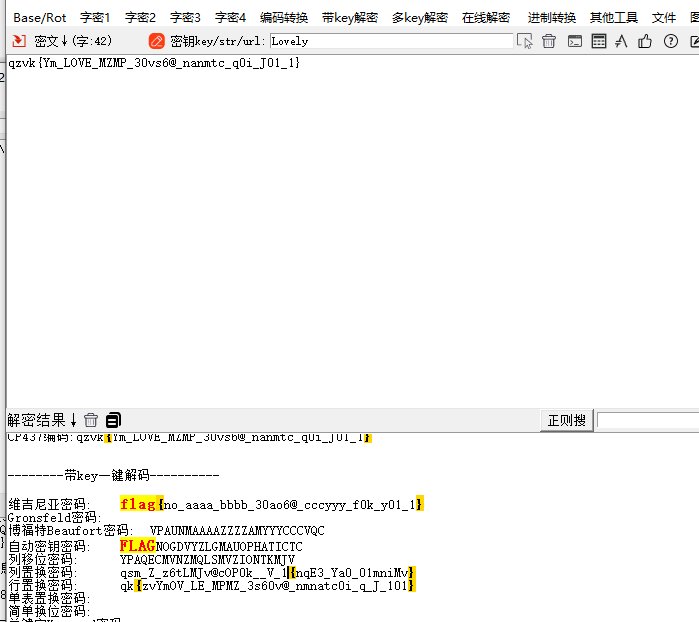
结合前面给的key,维吉尼亚一下就好(不能用一键的,一键解密的代码不一样,会变成全小写)
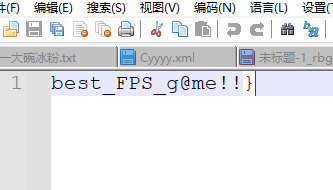
flag{No_AAAA_BBBB_30ao6@_cccyyy_f0k_Y01_1}
Hexagram Protocol
将图片丢给随波,发现exif信息有东西
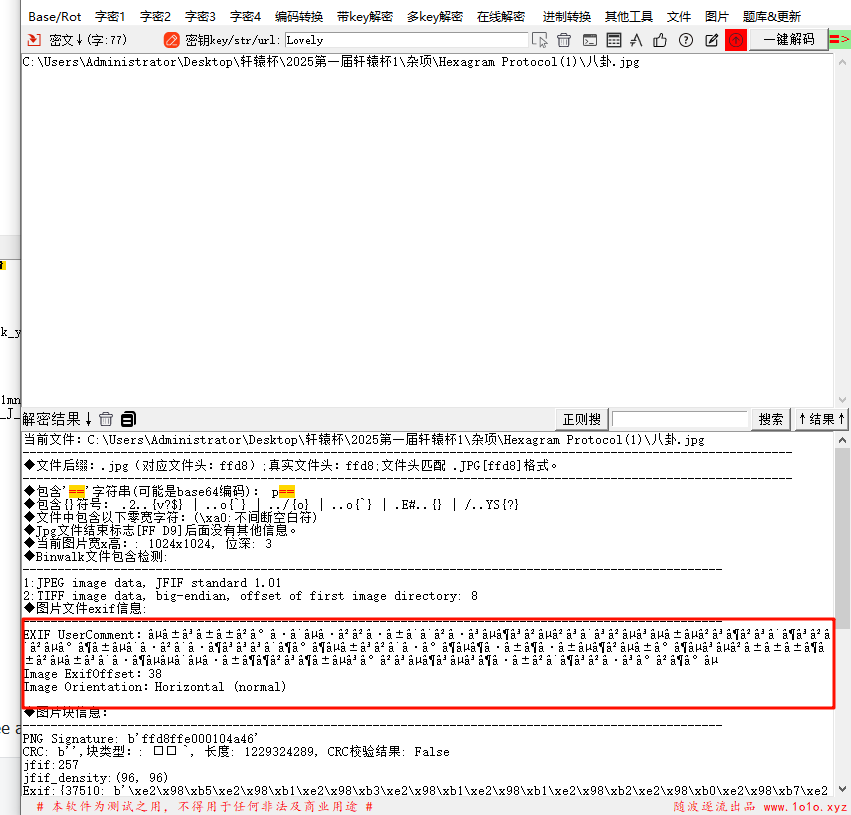
叽里咕噜的看不懂,丢给随波继续分析,发现可以解码出八卦
1☵☱☳☱☱☲☰☷☴☵☷☲☲☷☱☴☴☲☷☳☵☶☳☲☵☲☳☴☳☲☵☳☵☱☵☲☳☶☲☳☴☶☳☲☴☲☵☰☶☱☵☴☷☲☴☷☶☳☳☳☴☶☰☶☵☱☳☲☴☷☰☶☵☶☷☱☶☷☱☵☶☲☵☱☰☶☵☳☵☲☱☱☱☶☱☲☵☱☳☴☷☶☵☵☴☵☷☱☶☶☲☳☶☱☵☳☰☲☳☵☶☳☵☳☶☷☱☲☴☶☳☲☷☳☰☲☶☰☵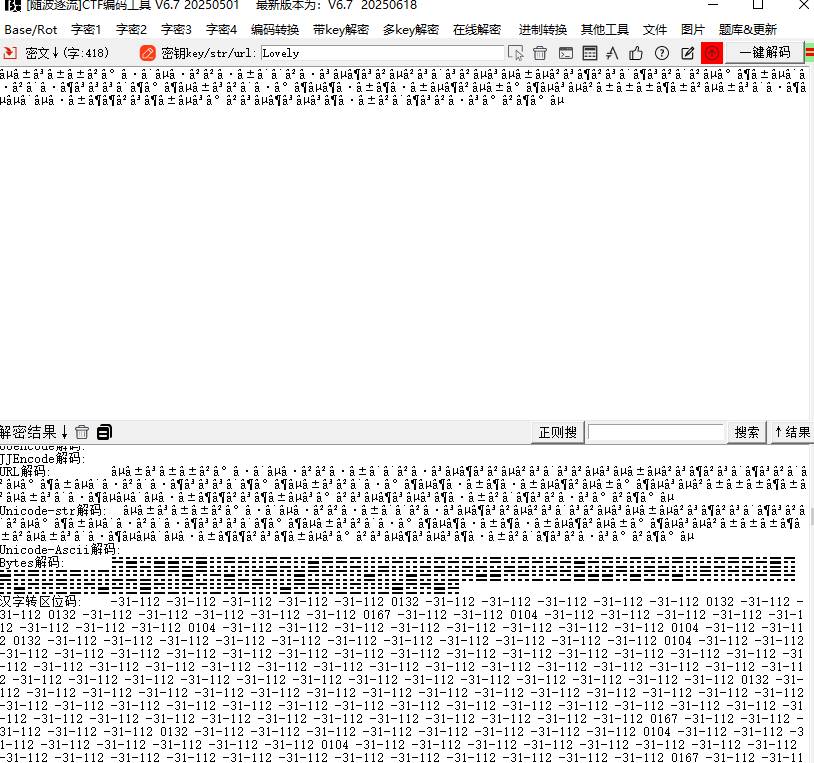
不难猜出是将八卦转为01字符串就好了,不过这里藏了坑,需要从下往上读取阴阳卦
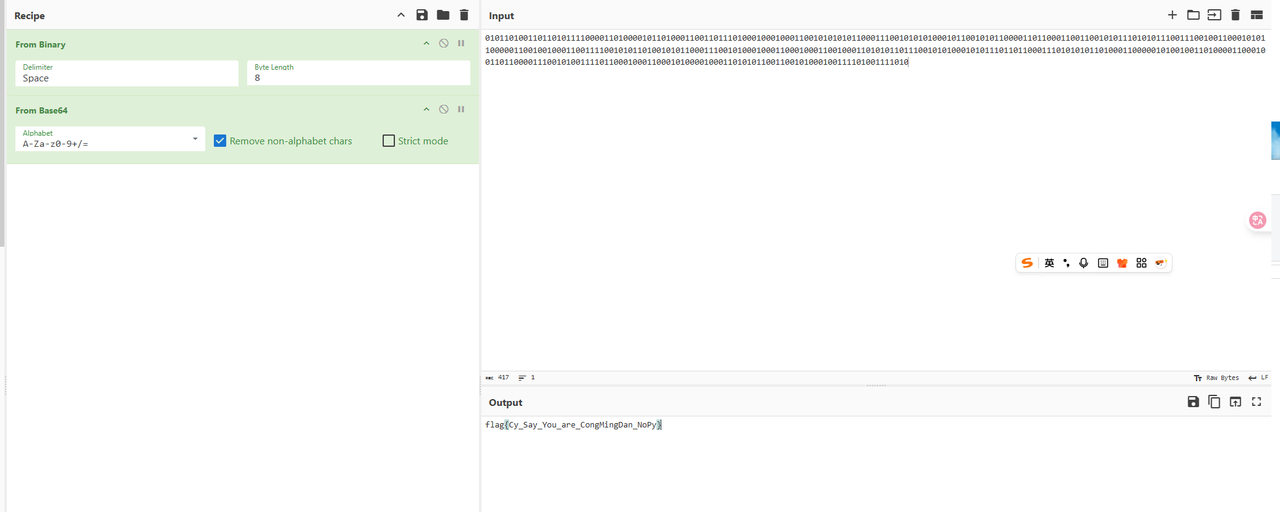
1010110100110110101111000011010000101101000110011011101000100010001100101010101100011100101010100010110010101100001101100011001100101011101010111001110010011000101011000001100100100011001111001010110100101011000111001010001000110001000110010001101010110111001010100010101110110110001110101010110100011000001010010011010000110001001101100001110010100111101100010001100010100001000110101011001100101000100111101001111010最后厨子梭哈一下就好
Terminal Hacker
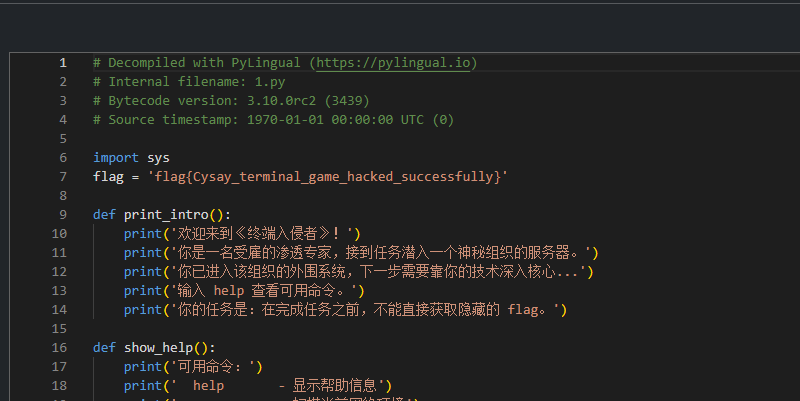
附件一看就是python打包的exe,反编译就好,先用pyinstxtractor反编译成pyc,然后丢给https://pylingual.io/
一大碗冰粉
内存取证,vol3分析一下,发现桌面有两个关键文件
1python vol.py -f ../whereicej3lly.raw windows.filescan | grep Desktop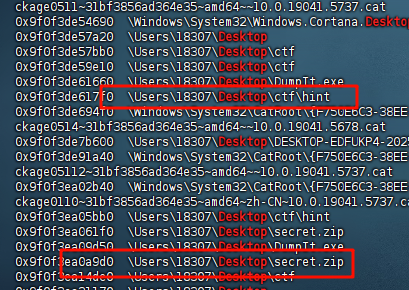
提取出来,发现一个加密压缩包,hint是,同时压缩包里面也有这个hint文件,直接bkcrack明文攻击

成功后解出压缩包
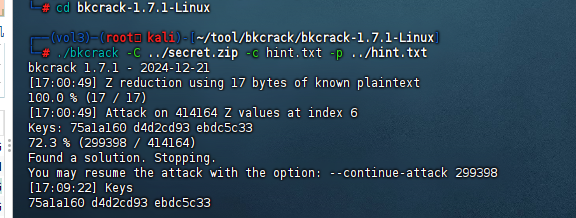
得到的压缩包里有个未知文件,根据名字推出是对search进行异或
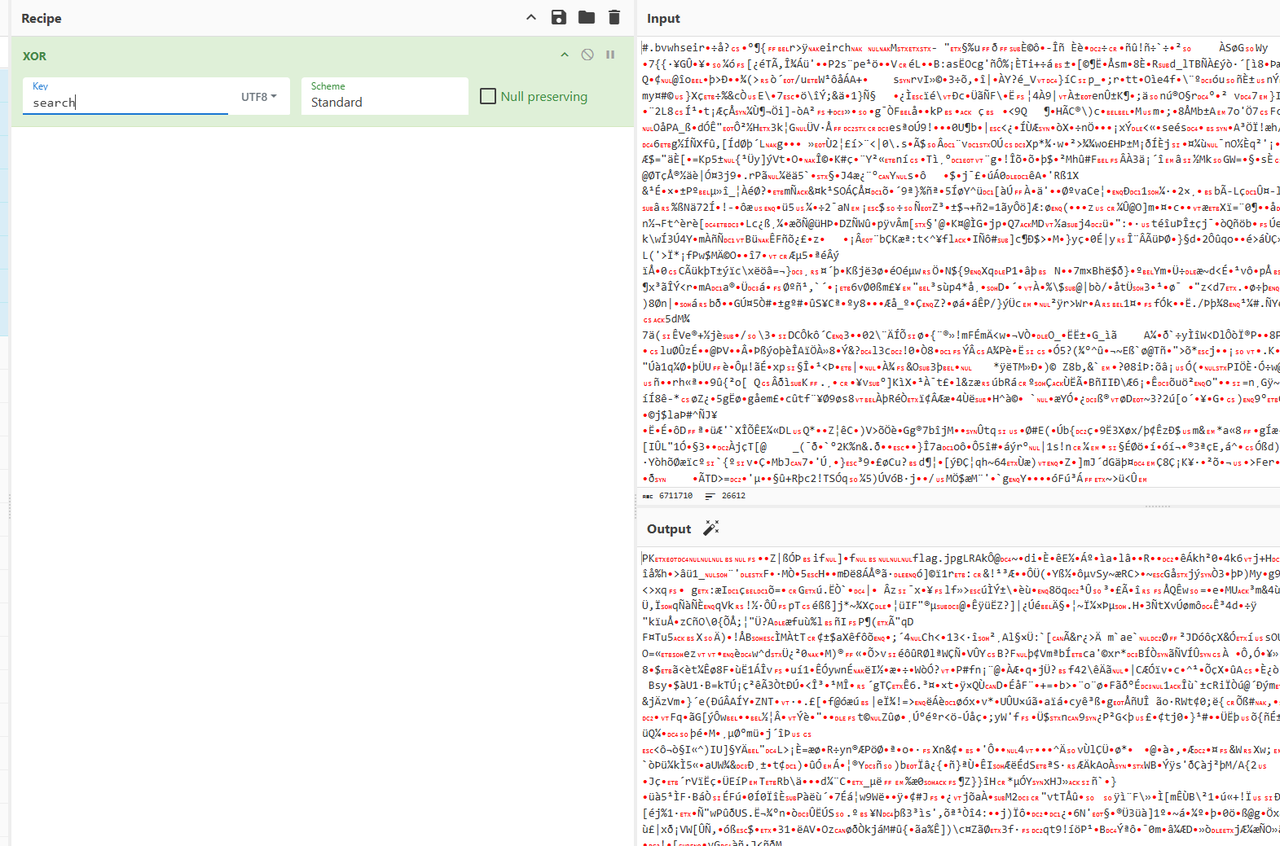
打开有个伪加密,修一下得到jpg图片,末尾告诉我们flag需要社工
看到远处有个辣抽抽烧烤还有一个酒店,锁定一下就能找到 江苏省连云港市海州区陇海步行街

哇哇哇瓦
附件一张图片,丢给随波,lsb得到一半

同时binwalk得到一个hint,那说明还有内容
看看图片,右下角有情况

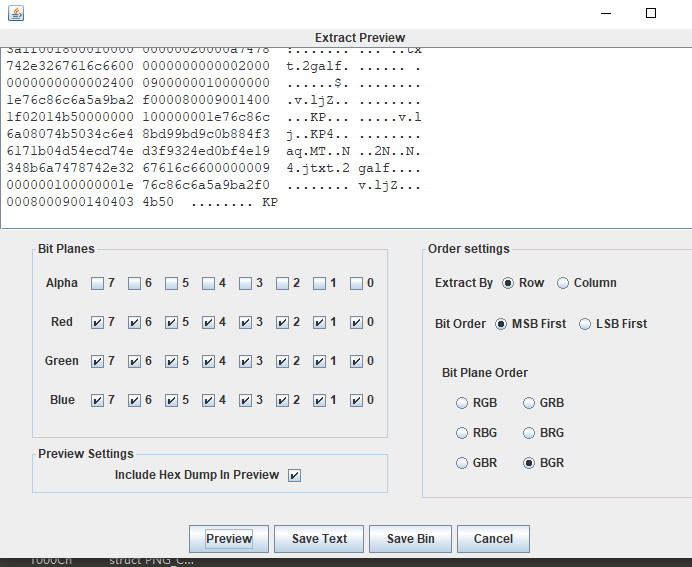
导出处理一下得到压缩包,用密码:GekkoYoru解压得到后半段flag
数据识别与审计
四种格式,各五个文件
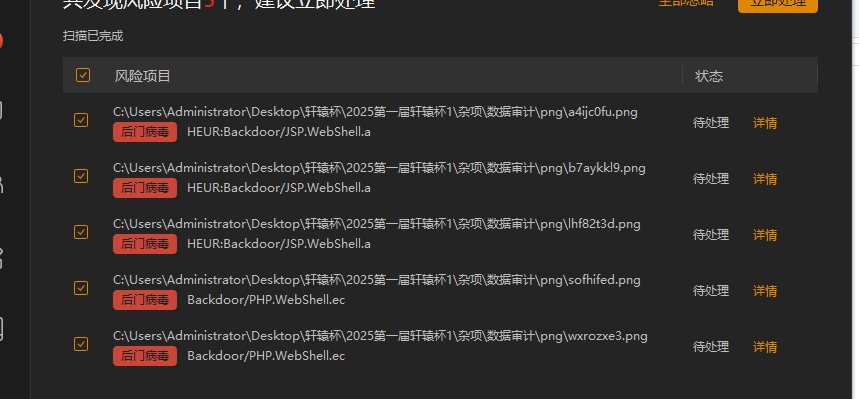
首先是png图片,用火绒查杀就可以得到5个图片
其次是wav,写脚本检测是否有声音得到五个音频
1import os
2import wave
3import contextlib
4import numpy as np
5
6def has_sound(file_path, frame_size=1024, threshold=300):
7 try:
8 with contextlib.closing(wave.open(file_path, 'rb')) as wf:
9 nchannels = wf.getnchannels()
10 sampwidth = wf.getsampwidth()
11 framerate = wf.getframerate()
12 nframes = wf.getnframes()
13
14 frames = wf.readframes(nframes)
15
16 # 支持16位或8位
17 if sampwidth == 2:
18 data = np.frombuffer(frames, dtype=np.int16)
19 elif sampwidth == 1:
20 data = np.frombuffer(frames, dtype=np.uint8) - 128
21 else:
22 print(f'不支持的采样位深: {sampwidth * 8}位')
23 return False
24
25 if nchannels > 1:
26 data = data.reshape(-1, nchannels)
27 data = data.mean(axis=1).astype(data.dtype) # 转为单通道
28
29 # 分帧判断:只要有一帧均值超过阈值就认为有声音
30 for i in range(0, len(data), frame_size):
31 frame = data[i:i+frame_size]
32 if len(frame) == 0:
33 continue
34 energy = np.mean(np.abs(frame))
35 if energy > threshold:
36 return True
37 return False
38 except wave.Error:
39 print(f'无法读取为有效的wav文件: {file_path}')
40 return False
41
42def check_wav_files(directory):
43 result = []
44 for filename in sorted(os.listdir(directory)):
45 if filename.lower().endswith('.wav'):
46 filepath = os.path.join(directory, filename)
47 if has_sound(filepath):
48 print(f'检测到声音: {filename}')
49 result.append(filename)
50 if result:
51 print('拼接结果:')
52 print(','.join(result))
53 else:
54 print('没有检测到任何有声音的文件')
55
56if __name__ == '__main__':
57 directory_path = './wav' # 修改为你的目录路径
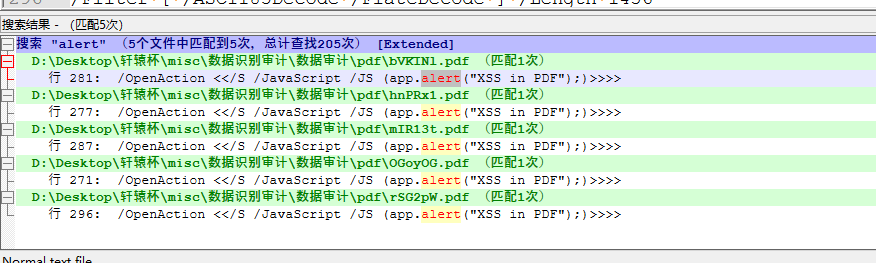
58 check_wav_files(directory_path)然后是pdf,notepad包搜alert发现五个pdf有
最后是txt,脚本读取过滤有数字或者英文的部分正好找出五个txt文档
1import os
2import re
3
4def contains_english_or_digits(text):
5 return re.search(r'[A-Za-z0-9]', text) is not None
6
7def scan_and_print_txt_files(directory):
8 matched_files = []
9
10 for root, _, files in os.walk(directory):
11 for file in files:
12 if file.lower().endswith('.txt'):
13 file_path = os.path.join(root, file)
14 try:
15 with open(file_path, 'r', encoding='utf-8') as f:
16 content = f.read()
17 except UnicodeDecodeError:
18 try:
19 with open(file_path, 'r', encoding='gbk') as f:
20 content = f.read()
21 except Exception as e:
22 print(f'[错误] 读取文件失败 ({file_path}): {e}')
23 continue
24 except Exception as e:
25 print(f'[错误] 读取文件失败 ({file_path}): {e}')
26 continue
27
28 if contains_english_or_digits(content):
29 print(f'--- 文件: {file_path} ---')
30 print(content)
31 print('--------------------------\n')
32 matched_files.append(file)
33
34 # 输出匹配的文件名列表
35 result = ','.join(matched_files)
36 print('匹配的文件名拼接结果:')
37 print(result)
38
39# 用法示例:替换为你要扫描的目录路径
40if __name__ == '__main__':
41 target_directory = './txt' # 修改为你实际的目录路径
42 scan_and_print_txt_files(target_directory)然后排列就行了
19h0zQJok.txt,FiBRFFnG.txt,gWa0DiTs.txt,Me4CoMw7.txt,T0BPOXDY.txt,a4ijc0fu.png,b7aykkl9.png,lhf82t3d.png,sofhifed.png,wxrozxe3.png,bVKINl.pdf,hnPRx1.pdf,mIR13t.pdf,OGoyOG.pdf,rSG2pW.pdf,Bd2IYe3.wav,bjVwvcC.wav,H0KDChj.wav,ou9E9Mh.wav,UEbzH4X.wav隐藏的邀请
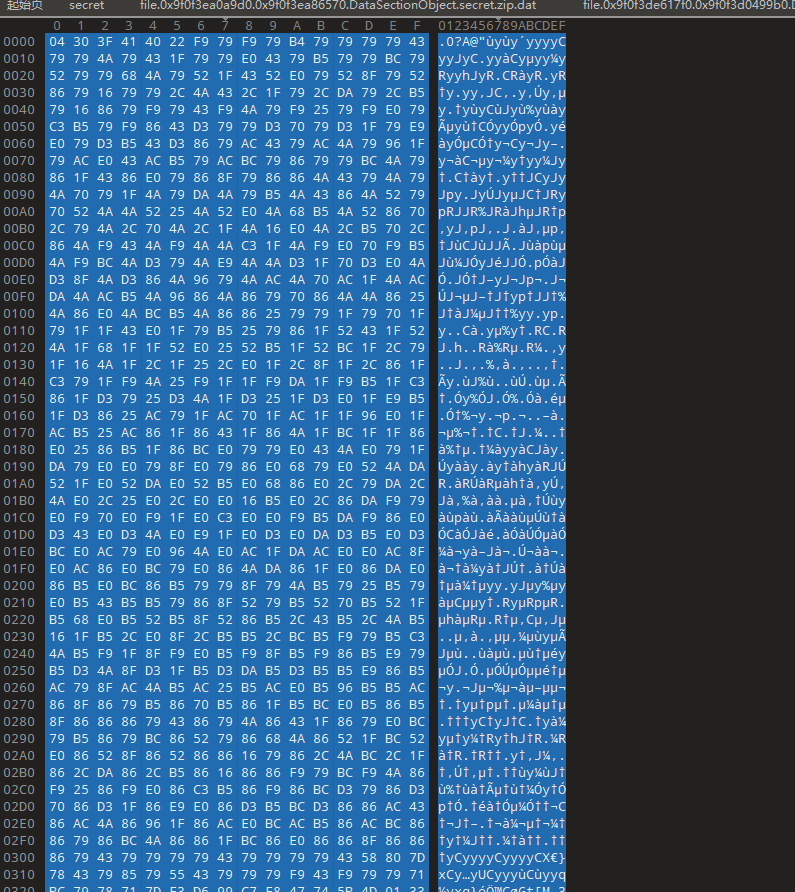
把docx解压,发现有一个cyyy.xml,打开里面有十六进制数据,丢给010
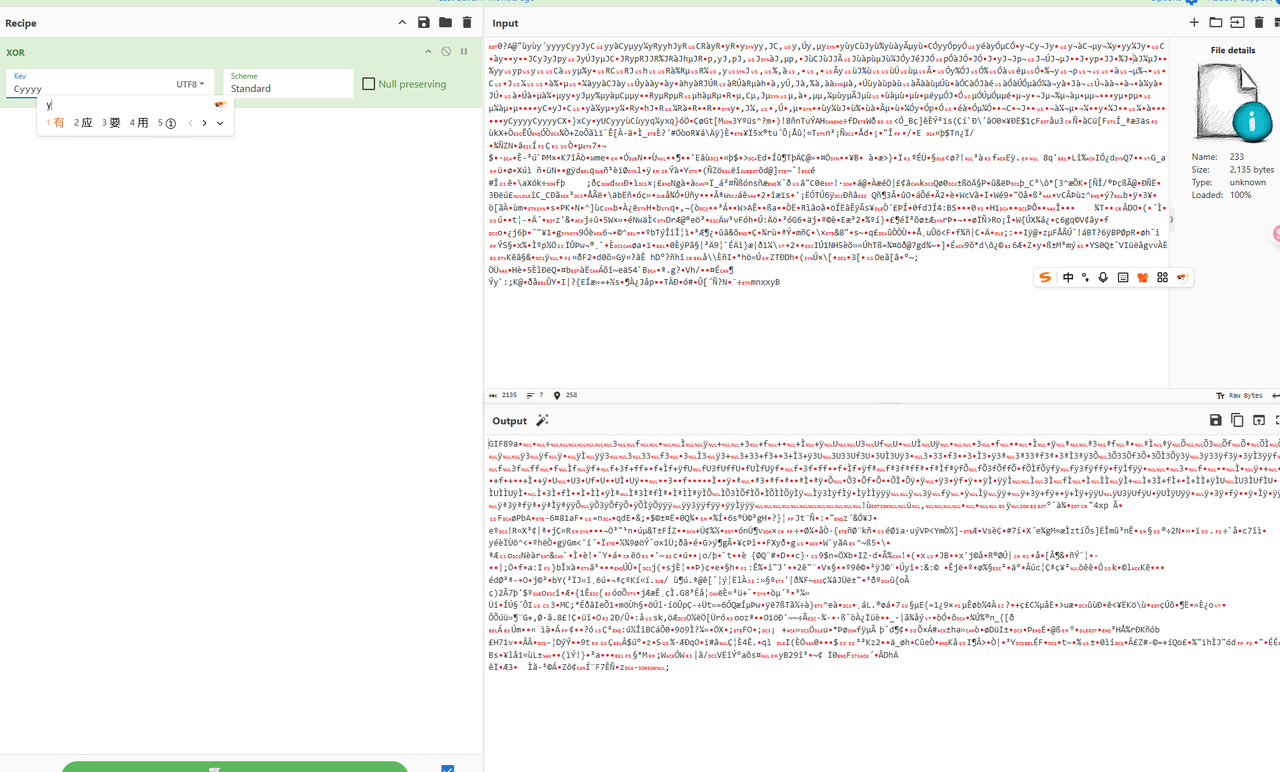
保存丢给厨子,异或Cyyyy,得到gif图
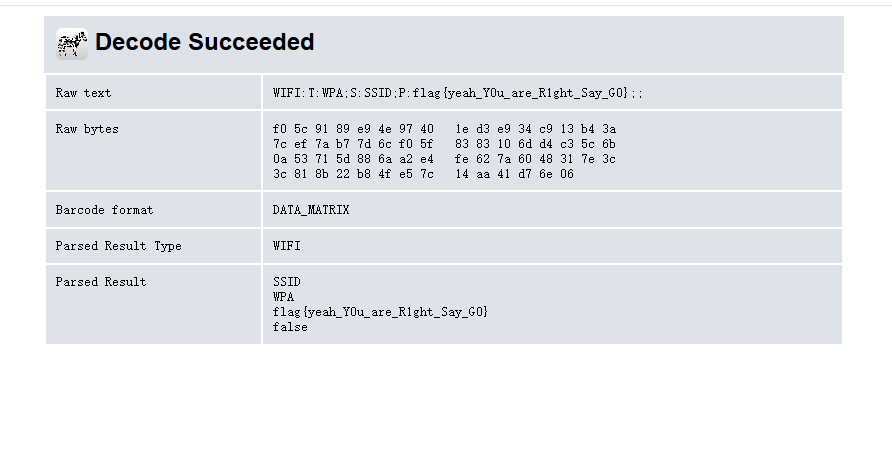
问gpt发现是数据矩阵码,直接在线解密
 本来是想看看题的,因为那会刚打完iscc实在是太伤了。但结果看到有实体奖品,最后还是燃尽了…… 这比赛我只能说,怎么也算半个iscc了,有些题目出的真的抽象,完全get不到作者脑洞,告白更是一绝,不好评价。
但他又给贴纸又有奖品,真是人民的好比赛)
本来是想看看题的,因为那会刚打完iscc实在是太伤了。但结果看到有实体奖品,最后还是燃尽了…… 这比赛我只能说,怎么也算半个iscc了,有些题目出的真的抽象,完全get不到作者脑洞,告白更是一绝,不好评价。
但他又给贴纸又有奖品,真是人民的好比赛)
Comments will be available soon.