2024春秋杯冬季赛-Day03-MISC方向WP
菜鸡碎碎念
第三天了,昨天因为在打西湖,所以把春秋杯放了~~(别问为什么西湖没wp,因为压根不会做)~~,春秋的题目一天比一天难的,不过今天的也算是勉强有点进展,第一题是比赛中做出来的,第二题则是后面在群友帮助下解出的(我自己解出大部分了其实就差最后一点),感觉还是很有意思的哈哈哈 难只是因为我太菜了,再接再厉吧 昨天如果也能打打的话排名应该能更前一点(希望我能拿个证书)

音频的秘密
知识点省流
本题考察弱口令 DeepSound加密 压缩包明文攻击 LSB隐写
WP
下载得到一个音频附件,根据提示,要用deepsound解密,同时存在密码,提示为弱口令,所以我随便猜了个123。没想到就中了
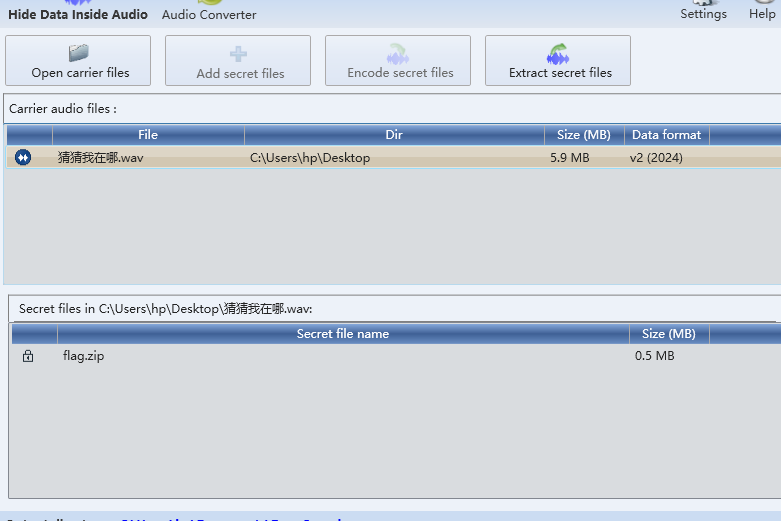
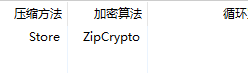
导出得到一个加密压缩包,里面是张png图片,这里设计一个明文攻击的知识点,这个压缩包的加密算法为ZipCrypto
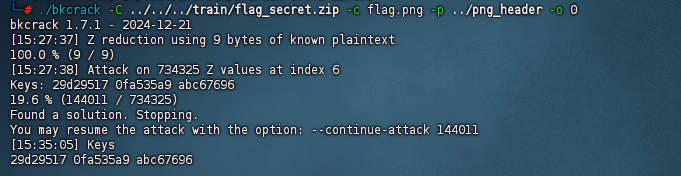
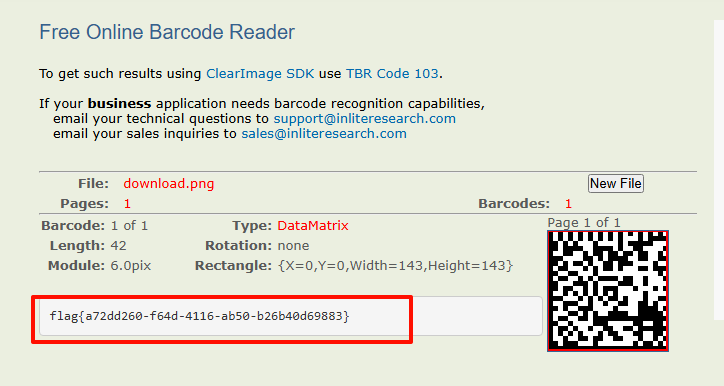
得到图片后,丢给随波逐流直接梭哈

Infinity
知识点省流
本题考察脚本小子 base58编码 SM4加密 DataMatrix码
WP
下载附件得到一张png图片,丢给随波逐流会发现文件末尾藏了一个压缩包,用binwalk或者直接提数据保存出来,然后打开压缩包会发现压缩包里面还有压缩包,套了很多层,需要写个脚本

让gpt写了个脚本跑,并且根据提示要用到base58解码
import os
import zipfile
import rarfile
import py7zr
import tarfile
from pathlib import Path
# 支持的压缩包格式
SUPPORTED_FORMATS = ['.zip', '.rar', '.7z', '.tar']
inf = ''
def extract_file(file_path, extract_to):
"""
解压一个文件到指定文件夹。
"""
file_extension = file_path.suffix.lower()
# print(file_path)
# 根据不同的文件格式选择解压方法
if file_extension == '.zip':
print(str(file_path)[21:-4])
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(extract_to)
elif file_extension == '.rar':
print(str(file_path)[21:-4])
with rarfile.RarFile(file_path) as rar_ref:
rar_ref.extractall(extract_to)
elif file_extension == '.7z':
print(str(file_path)[21:-3])
with py7zr.SevenZipFile(file_path, mode='r') as sz_ref:
sz_ref.extractall(extract_to)
elif file_extension == '.tar':
print(str(file_path)[21:-4])
with tarfile.open(file_path, 'r') as tar_ref:
tar_ref.extractall(extract_to)
else:
print(f"不支持的压缩包格式: {file_extension}")
def recursive_extract_folder(folder_path, output_folder):
"""
递归遍历文件夹,解压其中的压缩包到目标文件夹。
"""
# 遍历文件夹中的所有文件
for file in Path(folder_path).glob('*'):
if file.is_file() and file.suffix.lower() in SUPPORTED_FORMATS:
# print(f"发现压缩包: {file}")
# 为每个压缩包创建一个新的文件夹进行解压
extract_to = output_folder / f"{file.stem}" # 创建新的文件夹
if not extract_to.exists():
extract_to.mkdir(parents=True)
# 解压当前压缩包
# print(f"解压 {file} 到 {extract_to}")
extract_file(file, extract_to)
# 解压之后,继续递归处理解压出的文件夹
recursive_extract_folder(extract_to, output_folder)
def extract_all_compressed_files(zip_file_path, output_folder):
"""
从一个压缩包开始,递归解压所有压缩包到同一文件夹。
"""
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 解压初始的压缩包
print(f"解压初始文件 {zip_file_path} 到 {output_folder}")
extract_file(zip_file_path, output_folder)
# 递归解压解压出来的压缩包
recursive_extract_folder(output_folder, output_folder)
if __name__ == "__main__":
# 输入需要解压的压缩包路径和解压目标文件夹
zip_file_path = Path('./infinity/test.zip')
output_folder = Path('./infinity/')
# 开始解压
extract_all_compressed_files(zip_file_path, output_folder)
解压出来的压缩包文件显然是在base编码后的字符串拆分得到的,因此需要将其拼接起来,这里我直接在脚本执行时按顺序输出其名字,然后手动拼接,但发现没效果,想到试试反过来拼接(从最后一个压缩包名字往前接),先
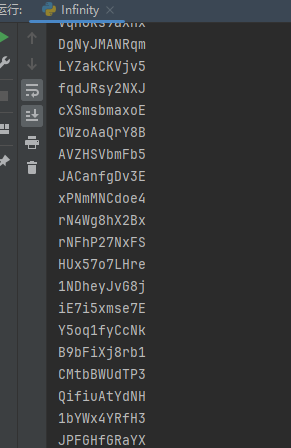
将脚本的输出保存在文本文档中,用linux的tac命令反向输出后再次保存,即可得到逆向拼接的字符串(省的改脚本了)
这时候再丢给厨子,就可以发现成功解码,然后就是需要用到sm4解密
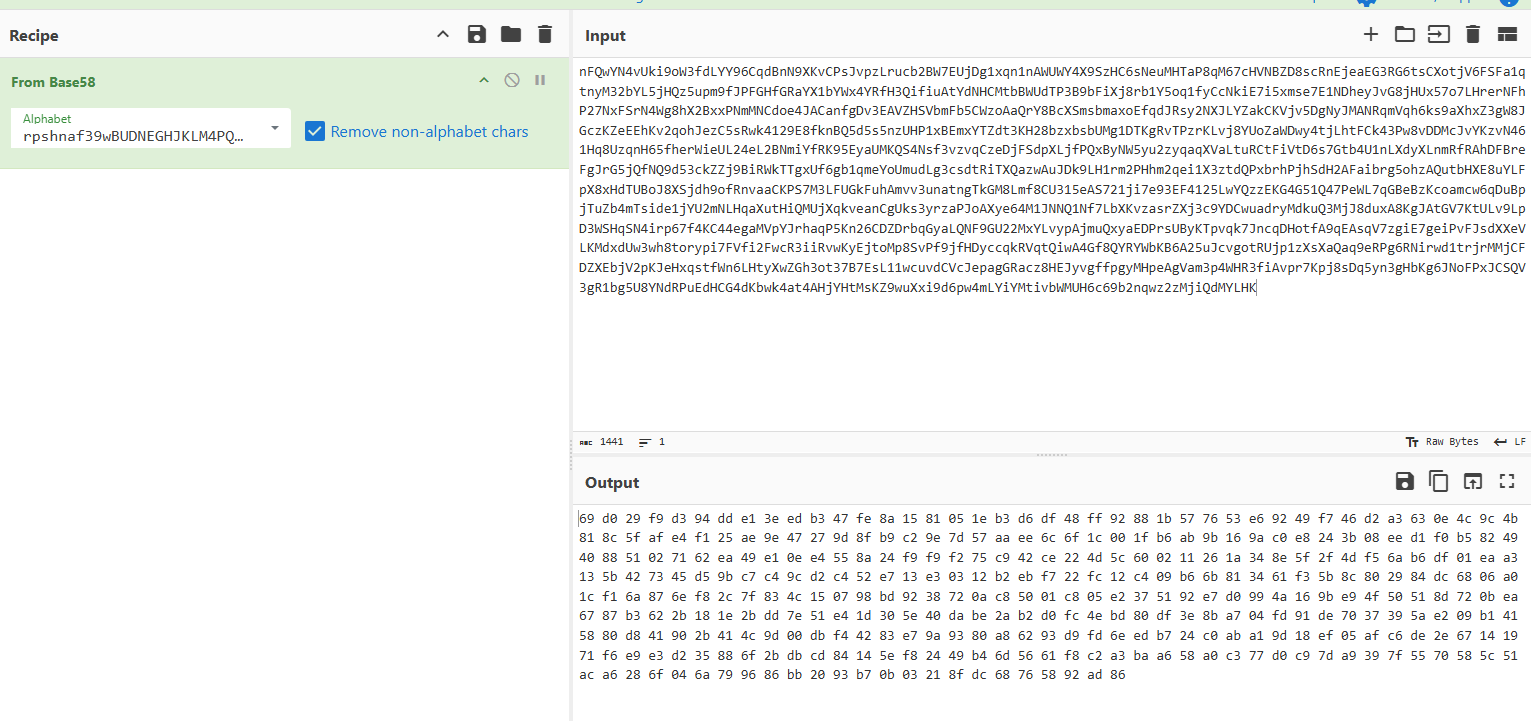
全部压缩包解压完后,最后一个压缩包内存了一个文档,里面的内容如下,而sm4解密是需要密钥的,猜测这个就是密钥
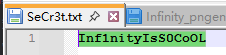
最后经过处理会得到一张png图片,而这张图片是一种DataMatrix码,找个在线网站处理
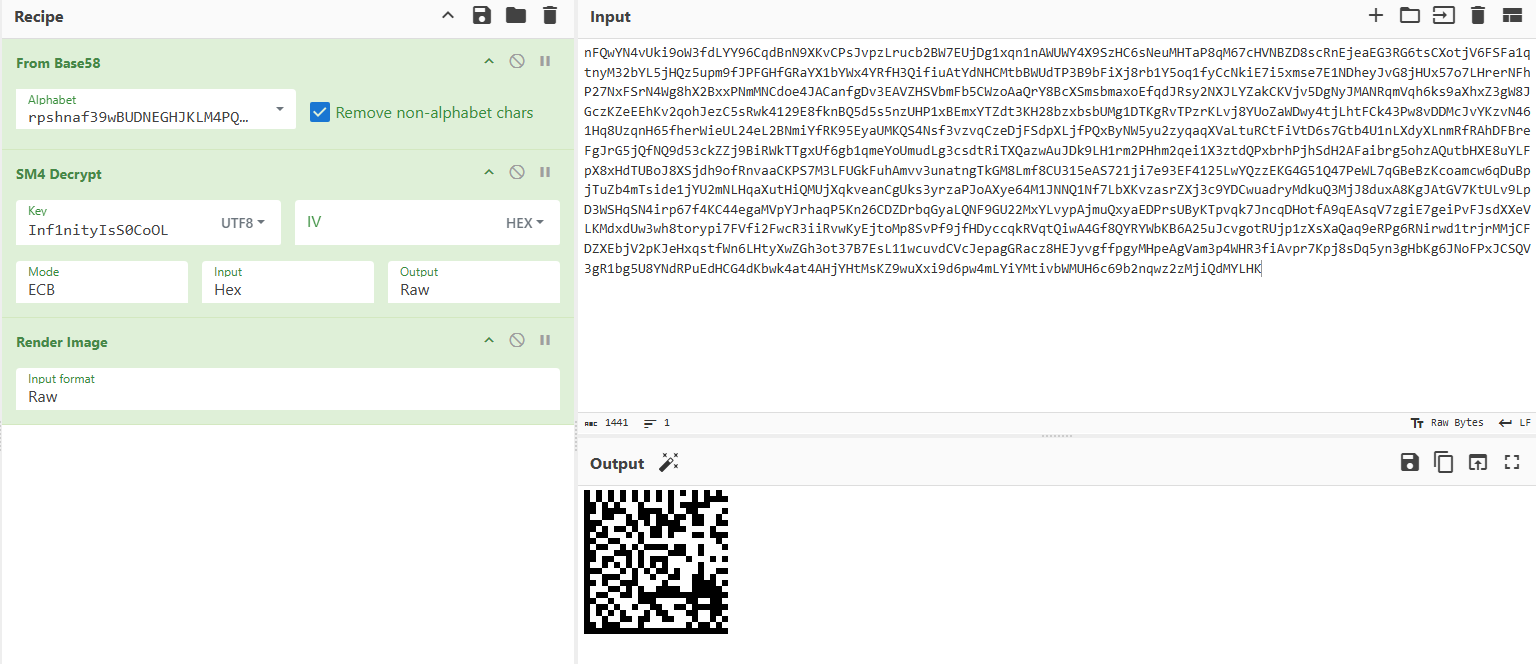
最后就能得到flag