
2025年能源网络安全大赛 - Misc - WriteUp&复现
碎碎念
因为当时忘记报这个比赛了)所以实际上并没有参加,是后面拿到题目附件复现的,这个比赛的题目难度有易有难吧,像是最后一个蓝牙协议是真不懂,也是后面看大佬wp复现的,又学到知识了
upload
知识点省流
ez流量分析
WP
wireshark打开直接在导出http对象里能看到有一张flag.png,导出来就是flag

超期未回收
知识点省流
脚本小子
WP
邑网杯一道题目的亲儿子),将超期未回收的账号数量统计即可,当回收时间小于最后使用时间且仍在激活的账号则视作超期未回收账号
跑个脚本统计即可
import csv
from datetime import datetime
def check_expired_accounts(file_path):
expired_accounts = []
with open(file_path, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
status = row['Status'].strip()
last_used_at_str = row['LastUsedAt'].strip()
expiry_date_str = row['ExpiryDate'].strip()
try:
last_used_at = datetime.strptime(last_used_at_str, '%Y-%m-%d').date()
expiry_date = datetime.strptime(expiry_date_str, '%Y-%m-%d').date()
except ValueError:
continue
if status == 'Active' and expiry_date < last_used_at:
expired_accounts.append(row)
print(f"flag{{{len(expired_accounts)}}}")
# 调用函数
check_expired_accounts('accounts.csv')
数据完整性校验
知识点省流
脚本小子
WP
根据题目提示,分别对a列和b列进行校验即可,ab列的校验算法不同,简单看看可以发现a列校验和是64位长度,而b列则是32位,可以分析出来一个是sha256加密,一个是md5加密
写个脚本对数据进行校验然后剔除不符合的数据量即可
import pandas as pd
import hashlib
df = pd.read_excel('data.xlsx', engine='openpyxl')
col_a = df.columns[0]
col_b = df.columns[1]
checksum_a = df.columns[2]
checksum_b = df.columns[3]
def sha256_checksum(value):
if pd.isna(value):
return ''
return hashlib.sha256(str(value).encode('utf-8')).hexdigest()
def md5_checksum(value):
if pd.isna(value):
return ''
return hashlib.md5(str(value).encode('utf-8')).hexdigest()
a_mismatch = 0
for idx, row in df.iterrows():
real_sum = sha256_checksum(row[col_a])
expected = str(row[checksum_a]).lower()
if real_sum != expected:
a_mismatch += 1
b_mismatch = 0
for idx, row in df.iterrows():
real_sum = md5_checksum(row[col_b])
expected = str(row[checksum_b]).lower()
if real_sum != expected:
b_mismatch += 1
result_str = f'A列-{a_mismatch};B列-{b_mismatch}'
print('校验结果:', result_str)
final_md5 = hashlib.md5(result_str.encode('utf-8')).hexdigest()
print('MD5值:', final_md5)
alarm_clock
知识点省流
磁盘取证+SSTV慢扫描+时钟方位绘图
WP
得到一个vmware的vmdk文件,随便找一个取证工具恢复里面的文件,比如diskgenius,发现有一个压缩包和一个wav文件,把他们提取
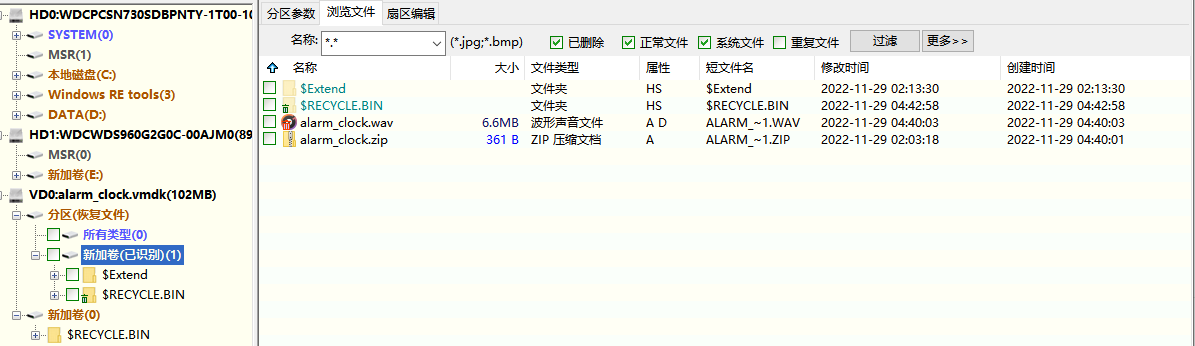
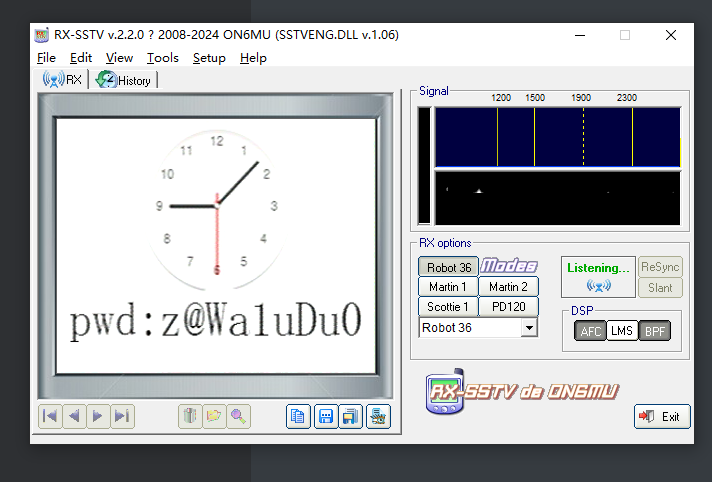
听一下音频会发现明显的刺耳的电波声,根据这个特征,猜测是sstv慢扫描,用rx-sstv扫描得到压缩包的密码

解压得到一个文档,其内容如下,其实不难看出,根据题目信息以及扫描得到的图片,一定与时钟有关,而数据中的数值范围在[0,11],正好对应了时钟的十二时,所以可以猜测是要根据时针的方位进行绘图,而第一行中的数据则可以表示为3点钟方向移动4格,9点钟方向2格,6点钟方向3格,0点钟方向4格,1点钟方向2格,5点钟方向2格,恰好是f
3,3,3,3,9,9,6,6,6,0,0,0,0,1,1,5,5
6,6,6,6,4,3,2
1,2,3,4,5,6,6,6,6,6,6,3,9,9,9,10,11,0,1,2,3,3
3,3,6,6,6,6,7,9,11,5,3,1,0,0,9,9,0,0
8,7,6,8,4,6,5,4
6,3,3,9,9,6,3,3,6,6,9,9
3,3,6,6,6,6,9,9,0,0,0,0,6,6,3,3
3,3,6,6,6,6
3,3,6,6,6,6,0,0,9,9,0,0
3,3,6,6,6,6,9,9,0,0,0,0
7,1,6,6,6,6,9,3,3
3,3,9,9,6,6,6,6,3,3,0,0,9,9
10,9,8,7,6,5,4,3,2
3,3
3,3,6,6,9,9,3,3,6,6,9,9
3,3,6,6,6,6,9,9,0,0,0,0
7,1,6,6,6,6,9,3,3
6,6,6,6,6,0,0,1,2,3,4,5,6,7,8,9,10,11,0
3,3
7,7,7,3,3,3,9,0,0,0,6,6,6,6,6
3,3,6,6,6,6,9,9,0,0,0,0,6,6,3,3
7,7,7,3,3,3,9,0,0,0,6,6,6,6,6
3,3,6,6,6,6,9,9,0,0,0,0
3,3
3,3,6,6,6,6,0,0,9,9,0,0
6,3,3,9,9,6,3,3,6,6,9,9
6,6,6,6,6,0,0,1,2,3,4,5,6,7,8,9,10,11,0
3,3,3,3,9,9,6,6,6,0,0,0,0,1,1,5,5
3,3
6,6,6,6,6,0,0,1,2,3,4,5,6,7,8,9,10,11,0
3,3,3,3,11,10,9,8,7,6,5,4,3,2,1
3,3,6,6,6,6
3,3,6,6,9,9,6,6,3,3
6,6,6,6,6,0,0,1,2,3,4,5,6,7,8,9,10,11,0
3,3,6,6,9,9,3,3,6,6,9,9
3,3,6,6,6,6
3,3,6,6,6,6,0,0,9,9,0,0
6,6,6,6,6,0,0,1,2,3,4,5,6,7,8,9,10,11,0
3,3,6,6,9,9,6,6,3,3
7,1,6,6,6,6,9,3,3
3,3,3,3,11,10,9,8,7,6,5,4,3,2,1
4,5,6,4,8,6,7,8
然后根据这个情况,让大模型写个脚本就好了
import math
import matplotlib.pyplot as plt
def get_step(clock_num):
"""根据时钟方向返回每一步的dx和dy"""
angle_deg = 90 - (clock_num % 12) * 30 # 转换为角度
angle_rad = math.radians(angle_deg)
dx = math.cos(angle_rad)
dy = math.sin(angle_rad)
return dx, dy
def process_line(line):
"""处理单行数据,生成路径点"""
digits = list(map(int, line.strip().split(',')))
if not digits:
return []
path = [(0.0, 0.0)] # 起始点
for d in digits:
dx, dy = get_step(d)
last_x, last_y = path[-1]
new_x = last_x + dx
new_y = last_y + dy
path.append((new_x, new_y))
return path
def main():
# 读取文件
with open('data.txt', 'r') as f:
lines = f.readlines()
# 生成所有字符的路径
all_paths = [process_line(line) for line in lines if line.strip()]
# 计算平移后的路径
shifted_paths = []
current_x = 0
spacing = 2.0 # 字符间隔
for path in all_paths:
if not path:
continue
xs = [p[0] for p in path]
min_x, max_x = min(xs), max(xs)
width = max_x - min_x
# 平移路径
shifted = [(x - min_x + current_x, y) for x, y in path]
shifted_paths.append(shifted)
current_x += width + spacing
# 绘图
plt.figure(figsize=(15, 3))
for shifted in shifted_paths:
xs = [p[0] for p in shifted]
ys = [p[1] for p in shifted]
plt.plot(xs, ys, 'k-', linewidth=2) # 用黑色线条绘制
plt.axis('equal') # 保持比例
plt.axis('off') # 隐藏坐标轴
plt.show()
if __name__ == '__main__':
main()

Bluetooth
知识点省流
蓝牙协议流量分析
WP
待补充


